AI 藝術完整歷史:從 AARON 到 Midjourney(1973–2025)
最後更新: 2026-01-22 18:07:34

人工智慧如何從學術研究的好奇心,蛻變為席捲全球的藝術革命,以及這一切為何值得你關注
本指南帶你回顧 AI 藝術從早期規則式系統一路演進到今日擴散模型的歷程,讓你清楚看見每一次關鍵突破,如何一步步改變藝術創作的可能性。
當機器人把藝術作品賣到近五十萬美元
2018 年 10 月,紐約佳士得拍賣行發生了一件前所未有的事。一幅略帶模糊、神似 18 世紀歐洲繪畫風格的肖像畫,以 43 萬 2,500 美元成交。買家是誰?匿名收藏家。賣家是誰?法國藝術團體 Obvious。那麼,藝術家是誰?答案令人震撼——是一個演算法。
《艾德蒙·德·貝拉米肖像》並非出自人類畫家之手,而是由生成對抗網路(GAN)訓練而成——模型學習了 15,000 幅歷史肖像畫。畫作角落的「簽名」也不是藝術家的名字,而是一段數學公式:「min max Ex[log(D(x))] + Ez[log(1 D(G(z)))]」。
藝術圈瞬間分成兩派。有人稱之為劃時代的里程碑,也有人斥之為噱頭,甚至是醜聞——尤其在外界發現該團體使用了開源程式碼,卻未妥善標註原作者 Robbie Barrat 之後,爭議更是甚囂塵上。然而,不論風波如何延燒,有一件事已無可否認:AI 生成藝術正式登場,而且這一次,潘朵拉的盒子再也關不上了。
但多數人不知道的是:2018 年那場拍賣,並不是 AI 藝術的起點,甚至差得很遠。這段故事其實要往前推 45 年——在一間大學的電腦實驗室裡,一位英國畫家覺得,傳統畫筆已經無法滿足他的創作野心。
快速時間軸:
1960s:早期電腦與演算法藝術的實驗,為後續發展奠定基礎
1973:Harold Cohen 啟動 AARON
2015: DeepDream + 早期風格轉換(Style Transfer)在網路上爆紅
2014–2018:GANs(生成對抗網路)大幅推進影像寫實度,AI藝術正式走進畫廊與拍賣市場
2021:CLIP 解鎖文字與影像的理解能力
2022:擴散模型(Diffusion models)+ Midjourney/DALL·E/Stable Diffusion,AI 藝術正式走入主流
2023–2025:著作權、資料集授權同意、作品溯源工具與監管相關的討論全面升溫
意外的先驅:一位畫家如何創造出史上第一位 AI 藝術家
Harold Cohen 與 AARON(1973–2016)

1968 年,哈羅德・科恩(Harold Cohen)正處於藝術生涯巔峰。他曾代表英國參加威尼斯雙年展,抽象畫作也在各大知名畫廊展出。然而,他心中始終有個揮之不去的念頭。正如他後來回憶的那樣:「也許,真正有趣的事情,並不只發生在我的畫室裡。」
Cohen 在 UC San Diego 任教期間接觸到電腦。他並不是把電腦當成數位化既有作品的工具,而是提出一個更根本的問題:電腦本身,能不能創作藝術?不是重製、不是複製,而是真正地 創造?
最終誕生的是 AARON,名稱部分取自《出埃及記》中摩西的兄弟亞倫。1974 年,哈羅德・科恩(Harold Cohen)首次在加州大學柏克萊分校展示 AARON 時,它還只能生成抽象圖樣。但真正革命性的地方在於:AARON 並非只是照表操課地執行預設指令。科恩將自己作為畫家所理解的構圖、封閉性與形式等概念轉化為規則寫入系統,而在這些規則之內,AARON 能夠自行做出創作決策。
可以這樣理解:Cohen 教會了 AARON 視覺語言的「文法」,但真正寫出句子的,是 AARON 自己。
到了 1980 年代,AARON 已能生成清晰可辨的圖像,包括人物、植物與室內場景。Cohen 會讓它透過一支機械繪圖手臂自由創作——這套裝置是在大學研究環境中與多位合作者共同打造,用來探索「程式碼如何在現實世界中作畫」。最終誕生的是一幅幅細節繁複的作品:每一張都獨一無二,每一張都一眼就能認出是 AARON 的風格,卻又沒有任何一張完全相同。
最迷人的是,Cohen 從來無法完全預測 AARON 會創作出什麼。他發現,某些程式指令竟生成了連他自己都未曾想像過的形態。這台機器正向他揭示:在他親手打造的藝術系統之中,仍存在著他尚未察覺的創作可能性。
AARON 持續演進超過 40 年。2001 年的版本已能生成色彩豐富的人物與植物場景;2007 年的版本(「Gijon」)則創作出宛如叢林般的風景。2016 年 Cohen 辭世時,他留下的不只是數以千計的作品,還拋出一個深刻的問題:當 AARON 能創作出連創作者本人都感到驚喜的全新構圖時,它是否已具備了「創造力」?
包括惠特尼美術館在內的多家重要藝術機構,曾展出與 Cohen 的 AARON 相關作品與紀錄,凸顯其在數位藝術史上的關鍵地位。直到今天,AARON 仍能持續生成影像,但凡是在 Cohen 過世後產出的作品,普遍被視為具有爭議性的「非原創」創作。
AARON 誕生之前:生成藝術與早期電腦實驗(1960 年代)
在今日這些模型出現之前,藝術家早已開始運用演算法來生成視覺形式。1960 年代的早期電腦繪圖機作品與以規則為核心的「生成藝術」,奠定了至今仍定義 AI 藝術的關鍵概念:藝術家設計的是一套系統,而真正產生超越人工重複的多樣變化,則交由系統完成。
沉潛的數十年:熱潮來臨前的 AI 藝術(1980年代–2000年代)
在 Cohen 專注於 AARON 的同時,其他藝術家也開始探索計算創造力,只是學術圈以外鮮少有人注意到。
Karl Sims 大概是這個時期在數位藝術圈中最接近「家喻戶曉」的人物。1980 年代他在 MIT Media Lab 工作,之後加入超級電腦公司 Thinking Machines,運用「人工演化(artificial evolution)」來創作 3D 動畫。他的方法是:先隨機生成 3D 形態,讓它們不斷變異,從中挑選出有趣的版本,再反覆進行。基本上,就是把自然選擇的概念套用在數位生物上。
他於 1991 年創作的《Panspermia》與 1992 年的《Liquid Selves》,在享譽國際的數位藝術殿堂 Ars Electronica 中雙雙奪下最高獎項。如果你曾看過那些令人著迷、彷彿有生命般流動的有機感 3D 動畫——看似不屬於自然界,卻又異常鮮活——那正是 Sims 所開創並奠定的美學風格。
Scott Draves 在 1999 年推出了截然不同的嘗試——「Electric Sheep」。沒錯,它是一個螢幕保護程式(還記得那是什麼嗎?),但重點是:它會學習。這個系統分散運行在成千上萬台電腦上,生成不斷演化的分形動畫,被稱為「sheep」。觀眾可以投票選出自己喜歡的圖樣,系統就會「繁殖」出更多相似風格的作品。有趣的是,它至今仍在運作。現在就造訪 electricsheep.org,你可以親眼看看。
在這段時期,「生成藝術」(generative art)一詞逐漸普及。藝術家開始透過撰寫程式碼,設定規則與參數,再交由演算法在這些限制中自行生成作品。2001 年專為藝術家打造的程式語言 Processing 問世,讓這類創作變得更加容易入門與普及。
但關鍵在於:對大多數人來說,這些其實並不算「AI」。它們的確是很酷的數位藝術專案,但看起來並不「聰明」。它們並不理解自己在創作什麼,只是在遵循一套再複雜不過的規則運作而已。
這一切即將改變。
深度學習徹底改變一切(2012–2015)
2010 年代初期出現了一個關鍵轉折點,有三個重要因素在此時匯聚:
首先,GPU(圖形處理器)的運算能力成長到足以訓練規模龐大的神經網路。諷刺的是,原本為遊戲而生的晶片,卻成了推動 AI 重大突破的關鍵引擎。
第二,大型資料集開始普及。2009 年推出的 ImageNet 收錄了數以百萬計的標註影像,讓神經網路第一次真正擁有足夠的範例,能有效學習並辨識其中的模式。
第三,深度學習演算法迎來了飛躍式的進步。2012 年,深度學習模型在影像辨識基準測試(因 ImageNet 而廣為人知)上取得突破性成果,全面擊敗傳統電腦視覺方法。這讓研究人員意識到一件事:只要神經網路夠「深」(層數夠多)、資料量夠大,再搭配足夠的運算能力,它們就能學會大規模的視覺模式,並開始展現出令人驚訝、近乎智慧的行為。
對藝術而言,其影響深遠。
Deep Dream 時刻(2015)
2015 年 6 月,Google 工程師 Alexander Mordvintsev 發表了一個相當「詭異」的實驗成果。他原本在研究如何將神經網路辨識物體的過程視覺化,於是提出一個反向思考:如果一個模型被訓練來辨識「狗」,那麼當我們反過來要求它把影像中所有看起來像狗的特徵不斷強化,會發生什麼事?
成果令人目眩神迷——迷幻、超現實,甚至帶著幻覺般的震撼。只要餵給它一張雲朵照片,神經網路就會在畫面中到處「看見」狗臉、眼睛與建築元素,並不斷放大強化,轉化成宛如夢境的超現實風景。藝術圈瞬間為之瘋狂。
Google 將這項技術命名為 DeepDream(正式名稱為「Inceptionism」)。短短幾週內,藝術家便開始打造一整個 DeepDream 藝術畫廊,逐漸形成一種獨特的美學風格——畫面中充滿眼睛與旋轉、有機感十足的紋理。即使到了今天,你依然能一眼認出那就是 DeepDream 的作品。
它在文化上的重要性,不只來自畫面本身,而是背後那個關鍵的領悟:這正是神經網路「看」世界的方式。它看到的,並不是人類眼中的事物,而是模式、關聯性與統計關係。而當這些模式被視覺化時,呈現出的樣貌,就像一場高燒中的夢境。
它怪得很徹底,但人們卻愛不釋手。
風格轉移:神經網路成為藝術家(2015–2016)
差不多在同一時期,研究人員也發現可以利用神經網路進行「風格轉換」(Style Transfer),把一張圖片的藝術風格套用到另一張圖片上。想看看你的照片變成梵谷《星夜》風格嗎?幾秒鐘就能完成。
這篇技術論文本身相當艱深(Gatys et al., 2015),但很快就有大量應用程式將其落地實現。2016 年,Prisma 爆紅,掀起風潮。從此,只要一支智慧型手機,人人都能創作出看起來像名畫風格的「藝術作品」。
批評者指出,這並不是真正「創作」新的藝術,而是演算法層面的模仿。然而,它首次證明了神經網路已能充分理解藝術風格,並將其重現出來——這一點,本身就是前所未有的突破。
GANs:引爆突破的關鍵技術(2014–2020)
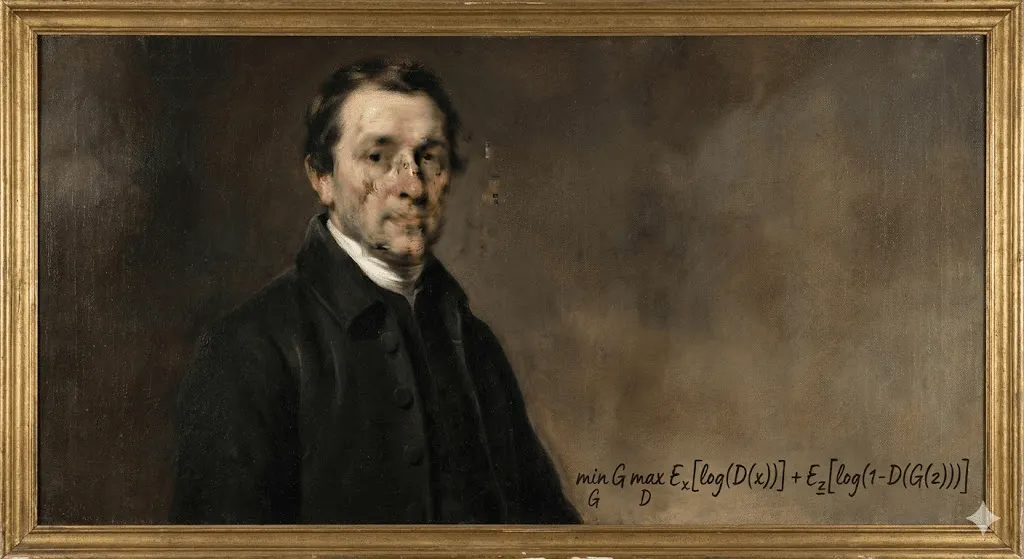
對藝術家而言,GANs 之所以重要,在於它讓「風格」能從資料中學習,讓你不必手動撰寫每一條規則,也能自在探索整個視覺宇宙。
不談數學,也能懂 GAN 的運作原理
2014 年,當時仍是蒙特婁大學博士生的 Ian Goodfellow 發表了一篇論文,首次提出「生成對抗網路(GAN)」概念,並迅速成為機器學習領域被引用次數最高的經典之一。深度學習奠基者 Yann LeCun 更直言,GAN 是「過去 10 年機器學習領域中最有趣的想法」。
核心概念是這樣的:想像兩個神經網路彼此對抗,進行一場博弈。
Network 1(the Generator): 負責生成看起來逼真的「假」影像,目標是以假亂真。
Network 2(判別器):負責分辨假影像與真實影像。
生成器一開始表現得很糟,只會產生隨機雜訊;判別器則輕而易舉就能識破假貨。但巧妙之處在於:生成器會從失敗中學習,不斷調整自己來欺騙判別器。判別器也隨之進化,更擅長分辨真偽;生成器再度調整。就這樣你來我往,反覆進行成千上萬次。
最終,生成器(Generator)強大到連鑑別器(Discriminator)都無法穩定分辨真假。到了這一步,你就擁有一個能從零開始生成逼真影像的神經網路。
關鍵突破在於:GAN 不再需要人類為每一種可能的輸出進行標註訓練。它們能學習訓練資料背後的統計分佈,不論是人臉、風景或其他影像,都能在此基礎上生成近乎無限的變化。
從怪異臉孔到以假亂真的藝術(2015–2018)
早期的 GAN 成果嘛……只能說相當「實驗性」。如果你還記得 2015 年前後那些讓人作惡夢的 AI 生成人臉——五官扭曲、充滿詭異感、完美命中恐怖谷——那就是早期 GAN 的樣貌。研究人員原本只是把它們當作概念驗證分享,結果很快就在網路上被瘋傳,成了經典迷因。
不過,技術進步的速度驚人。到了 2017 年,NVIDIA 推出的 Progressive GAN 已能生成 1024×1024 的人臉影像,幾乎與真實照片難以分辨。2018 年,StyleGAN 更進一步,不僅將解析度推向新高,還讓創作者能精細控制影像的不同細節層面。
藝術家開始展開各種實驗。德國藝術家 Mario Klingemann 創作了《Memories of Passersby I》(2018),這是一件由兩個螢幕組成的裝置藝術,持續生成無限變化的人像。畫面如同記憶般不斷滑過,永不重複。該作品最終於蘇富比拍賣,以 40,000 英鎊成交。
Helena Sarin 則選擇了不同路徑:她不是用照片,而是以自己的手繪作品來訓練 GAN。這讓她在運用 AI 生成能力的同時,依然牢牢掌握創作主導權。她的「AI Candy Store」系列呈現出一眼就能辨識的 AI 風格,但其中已深度融合她獨有的藝術語彙。
Robbie Barrat 當時仍是高中生,便開始以古典藝術訓練 GAN,並將程式碼公開分享在 GitHub 上。(後來 Obvious 正是使用這套程式碼參與佳士得拍賣,引發了關於署名與藝術創作歸屬的廣泛爭議。)
下一個林布蘭 (2016)
在 Obvious 掀起拍賣話題之前,早在 2016 年就有《The Next Rembrandt》這個計畫。這是由 ING 銀行與多個荷蘭機構共同發起的行銷專案:他們數位掃描了林布蘭 346 幅畫作,訓練演算法理解其創作風格,最終生成了一幅「全新的」林布蘭肖像。
嚴格來說,它並不是 GAN,但核心概念非常接近:AI 能否創作出特定藝術家的風格?這個專案引發了大量媒體關注。評論界一方面肯定其技術突破,另一方面也質疑:這究竟算是藝術,還只是高度精巧的風格模仿。
它拋出了我們至今仍在思考的關鍵問題:以特定藝術家的作品來訓練模型,究竟是致敬與傳承,還是演算法式的挪用?靈感,究竟從什麼時候開始變成了剽竊?
大爆發:AI 藝術走入主流(2022–至今)
CLIP:教會 AI 理解文字與影像(2021)
下一個重大突破出現在 2021 年 1 月,由 OpenAI 推出:CLIP(Contrastive Language–Image Pre-training)。其技術原理相當複雜,但帶來的影響卻非常直觀——CLIP 讓 AI 開始真正理解「文字」與「影像」之間的關聯。
過去的系統仰賴人工標註資料,例如「這是一隻貓」、「這是一隻狗」。CLIP 則是從網路上蒐集的 4 億組圖像與文字配對中學習,理解哪些詞彙常與哪些視覺特徵一起出現,進而建立一個文字與影像能彼此對照、比較的共享「空間」。這正是它的關鍵突破。
為什麼這很關鍵:把 CLIP 與生成模型結合,影像就能從文字描述直接誕生。只要輸入「一名太空人騎著馬」,系統就知道該呈現成什麼樣子。
藝術家很快就把 CLIP「駭」進自己的創作流程,搭配 GAN 或其他生成模型,開始用語言來引導影像生成。過程不算流暢、操作也有點笨重,但確實行得通。
2022 年的革命:DALL E 2、Midjourney、Stable Diffusion

接著來到 2022 年,一切在一夕之間徹底改變。
DALL E 2(OpenAI,2022 年 4 月)結合了 CLIP 與擴散模型(稍後會再介紹),能直接從文字生成高品質且高度一致的影像。初期僅開放給部分藝術家與研究人員搶先體驗,候補名單迅速暴增至百萬人以上。OpenAI 公開展示的作品創意十足、畫面完整,往往令人驚艷,甚至美得不可思議。
Midjourney(Midjourney Inc., 2022 年 7 月)則走出了一條截然不同的路線:以社群為核心、以 Discord 為平台,專注於視覺美感與風格表現。它很快形成了極具辨識度的風格——繪畫感強烈、戲劇張力十足,並充滿奇幻色彩,吸引大量藝術創作者湧入。其 Discord 伺服器也迅速成為網路上最活躍的創作社群之一。
Stable Diffusion(Stability AI,2022 年 8 月)徹底改變了 AI 繪圖的可及性。不同於 DALL·E 2(僅限網頁、受控存取)或 Midjourney(訂閱制),Stable Diffusion 採用開源模式,任何人都能下載、在本地端運行,甚至自行修改與延伸。
短短數月內,一整個生態系迅速成形:網頁介面、行動 App、Photoshop 外掛,以及數百個為特定風格量身訓練的客製化模型。這樣的爆發速度,前所未見。
到了 2022 年底,社群媒體幾乎被 AI 藝術洗版。「Prompt 工程」成了一門新技能,大家熱烈分享如何下指令才能生成更好的作品。同時,關於 AI 究竟是在讓藝術更民主,還是在摧毀藝術本質的爭論,也從未停過。
擴散模型:魔法背後的關鍵技術
那麼,什麼是擴散模型(diffusion model)?其實它的靈感來自物理學,特別是粒子在介質中擴散的過程。
訓練過程:
- 先取得一張真實影像
- 逐步加入雜訊,直到影像變成完全隨機的靜態雜訊(正向擴散)
- 訓練神經網路反向還原這個過程,將雜訊一步步移除(反向擴散)
生成流程:從純隨機雜訊開始,透過反向擴散過程逐步還原,最終生成一張結構完整、可辨識的影像。文字條件(透過 CLIP)負責引導生成方向,決定最後呈現的是哪一種類型的畫面。
為什麼在這個應用上擴散模型勝過 GAN:訓練更穩定、上手更容易,且更能精準理解並回應文字提示。GAN 仍在部分場景中持續使用,但在 2022 年那波爆發中,擴散模型成為主流。
技術補充說明:關鍵論文是 Ho 等人在 2020 年發表的〈Denoising Diffusion Probabilistic Models〉,而更早之前 Sohl-Dickstein 等人於 2015 年的研究已奠定基礎。如果你想真正深入理解這套技術,這些論文都是很好的起點——但先提醒一下,數學內容相當硬核。
關鍵數字
- 到了 2023 年初,這些工具已吸引數百萬用戶,AI 生成影像開始大量充斥各大社群平台。
- DALL·E:超過 300 萬名用戶(候補名單已全面開放)
- Stable Diffusion:難以精確統計(開源、去中心化散布),但從 GitHub 數據推估,使用者規模已達數百萬
人們用 AI 生成了數以億計的影像,各式各樣的 AI 藝術服務迅速成形,甚至發展成完整的商業模式。圖庫平台忙著制定應對政策,而傳統藝術家則在錯愕中看著「AI 藝術家」成為一個正式的職稱。
另一條 AI 藝術路線:學術與研究應用
當大眾的目光都集中在文生圖工具時,研究人員其實早已悄悄運用 AI,徹底改變藝術史研究的方式。這條 AI 藝術史的支線雖然較少被討論,卻在學術層面上具有不可忽視的重要性。
用於創作歸屬判定與分析的電腦視覺
藝術史學家長期以來都為作品的歸屬問題傷透腦筋——究竟是誰創作了這件作品?如今,神經網路正開始提供助力。
Rutgers Art & AI Lab(由 Ahmed Elgammal 領導)開發了一套系統,能分析筆觸、構圖元素與風格特徵,用來辨識藝術家身分或檢測贗作。2017 年,在受控測試中,該系統對未標註作品的作者判定準確率超過 90%。
失落作品的重建:透過以藝術家既有作品訓練的神經網路,AI 能生成相對合理的「推測性重建」,模擬遺失或受損作品可能的原貌。最知名的案例是運用 AI 推演林布蘭《夜巡》在 1715 年遭裁切前的樣子,展示被切除區域可能呈現的構圖。(當然,藝術史學界對其準確性仍有爭論——這屬於基於資料的推測,而非真正的復原。)
赫庫蘭尼姆卷軸(Herculaneum Scrolls):2023 年,電腦科學家運用機器學習技術,成功解讀西元 79 年維蘇威火山爆發時被碳化的古代卷軸文字。這些卷軸極度脆弱,無法實際展開,但透過 CT 掃描結合訓練完成的神經網路,AI 得以辨識其中的墨跡結構。這代表人類首次在近兩千年後,重新閱讀這批失落已久的古文獻。(資料來源:Nature,2023)
博物館與 AI
各大重量級機構以各種令人驚豔的方式實驗並運用 AI:
大都會藝術博物館(The Met)曾嘗試以 AI 驅動的館藏視覺化,將龐大的博物館典藏映射進「潛在空間(latent space)」,用來揭示作品之間意想不到的關聯。:這是一項由大都會藝術博物館、MIT 與藝術家 Refik Anadol 共同合作的計畫。他們以神經網路訓練 The Met 全部館藏(超過 37.5 萬件藝術品),並將不同作品類型之間的概念領域,也就是所謂的「潛在空間」加以視覺化。結果發現了許多令人驚喜的連結:例如一件古代波斯水壺,可能在概念上與 19 世紀的花瓶非常接近,這些關係往往是人類策展人過去未曾察覺的。
MoMA 的 AI 實驗:Refik Anadol 的《Unsupervised》(2022–2023)以 MoMA 館藏資料訓練機器學習模型,在博物館大廳生成流動、如夢似幻的影像投影。藝術圈對此看法兩極:有人認為只是噱頭,也有人視之為重新體驗博物館典藏的全新方式。
慕尼黑大學(LMU)的「透明 AI 計畫」:由 Hubertus Kohle 教授領導,這項研究致力於開發可解釋其推理過程的藝術史 AI 工具。傳統神經網路常被稱為「黑盒子」——只給你結果,卻不知道為什麼。這個計畫讓 AI 的判斷過程變得透明,對學術界的認可至關重要。團隊正在訓練模型,不僅能辨識藝術作品之間的視覺相似性,還能清楚說明哪些視覺特徵促成了這些判斷。
這些應用並不直接生成新的藝術作品,卻正在改變我們研究藝術史的方式;其影響力,或許比任何生成的影像都更為長久。
爭議焦點:著作權、倫理,以及創作的未來

事情從這裡開始白熱化。技術上的突破令人驚嘆,但隨之而來的倫理爭議,卻變得相當複雜。
著作權之戰
關鍵問題在於:AI 藝術模型是以從網路上蒐集的數十億張圖片進行訓練,其中許多都受著作權保護。創作者從未被徵詢同意,也沒有獲得任何報酬。然而,這些以他們作品為養分的系統,卻能在短短幾秒內生成「他們風格」的圖像。
重大訴訟案陸續提起:
Getty Images vs. Stability AI(2023 年 1 月):Getty 指控 Stability 在訓練 Stable Diffusion 時,未經授權抓取數百萬張 Getty 圖庫影像,並提出證據指出,部分生成圖片中仍殘留可見的 Getty 浮水印,明確顯示其來源。
藝術家集體訴訟 Midjourney、Stable Diffusion、DeviantArt(2023 年 1 月):由藝術家 Sarah Andersen、Kelly McKernan 與 Karla Ortiz 發起,指控相關平台涉及大規模著作權侵權。案件截至 2024 年底仍在審理中,法律界對最終判決走向意見分歧。
法律上的關鍵問題在於:以受著作權保護的圖像來訓練 AI,究竟算不算合理使用(就像學生透過研究既有藝術作品來學習),還是構成侵權(未經授權,將他人作品用於商業利益)?
法院目前尚未做出裁定,而最終的答案將深刻影響整個產業的走向。
藝術家回應:反擊行動
藝術家不再等待法院裁決,而是主動研發技術層面的反制措施。
Glaze(University of Chicago,2023):一款軟體,能以人眼難以察覺的方式微幅改動數位藝術作品,卻能「毒化」AI 的訓練過程。當模型使用經過 Glaze 處理的影像進行訓練,輸出結果就會出現扭曲。就像是一種主動式浮水印,不是用來識別,而是用來干擾與破壞。
Nightshade(亦由芝加哥大學 U of Chicago 於 2023 年提出):比 Glaze 更為強勢。不僅保護套用 Nightshade 的圖片,還會主動削弱模型的整體表現。當你上傳足夠多被標註為「狗」、實際卻是貓的 Nightshade 圖片,模型最終會對「狗」的外觀產生混淆。
這些工具一直備受爭議。AI 研究人員認為它們可能造成破壞與風險;藝術家則視其為自我防衛的手段。雙方其實都有各自的立場與理由。
「Do Not Train」提案:藝術家與倡議者提出在作品中加入中繼資料標記,明確標示不得用於 AI 訓練。部分平台(如 DeviantArt、Shutterstock)已提供選擇退出(opt out)機制,但實際執行力道有限。AI 公司往往可以直接忽略這些標記,且確實有不少這麼做。
創意之辯
比版權更深層的,其實是一個哲學性的提問:AI 生成的作品,真的能被稱為藝術嗎?
反對的論點:
- 缺乏人類的創作意圖與情感深度
- 只是重組既有作品,而非真正創造全新的表達
- 不需要專業技能,任何人都能輸入指令生成
- 削弱藝術的核心價值——人類的創造力與創作歷程
支持它是藝術的論點:
- 工具不會讓藝術失去價值(就像相機的出現並沒有終結繪畫)
- 提示詞設計與作品篩選本身就是一種專業能力
- 人類仍然主導 AI,在過程中做出關鍵的創作判斷
- 開啟過去無法想像的全新表現形式與創作可能
我的看法:這其實是個問錯方向的爭論,就像 1850 年在吵「攝影算不算藝術」一樣。事實很明顯——AI 已經能創作藝術了,我們都看見了。真正值得討論的不是「能不能」,而是:人類與機器的創造力,未來應該建立什麼樣的關係?誰會因此受益?又有什麼會被犧牲?同時,又有哪些全新的可能被打開?
工作被取代的現實
這不是紙上談兵,而是真真切切有人因此失去工作。
Concept Art Association 於 2023 年的一項調查發現:
- 73% 的概念藝術家表示工作機會明顯減少
- 62% 曾因 AI 而失去自由接案機會
- 入門級職位消失速度最快
企業開始用 AI 來完成前期概念發想、分鏡草圖、背景設計——這些原本多半交給剛入行的創作者負責的工作。有些支持者認為,這和數位工具取代傳統技法並沒有本質差異;但不可否認的是,變化的速度前所未見,也難怪受到衝擊的藝術家會感到憤怒與不安。
另一方面,也出現了全新的職務角色:AI 藝術總監、Prompt 工程師,以及專精於人類與 AI 協作流程的專家。這些新興工作是否能以一比一的比例補足被取代的職位,仍有待時間驗證。
偏見問題
AI 藝術模型會承襲訓練資料中的偏見。當你要求生成「一位 CEO」,出現的多半是白人男性;輸入「一名護理師」,畫面往往是女性;而「一個漂亮的人」,則高度集中在年輕、白人、符合主流審美的臉孔。
Google 的 Gemini 在 2024 年嘗試透過提升歷史影像的多元性來修正問題,卻出現嚴重過度校正,引發外界對模型如何在歷史準確性、族群呈現與安全性之間取得平衡的爭議。這起事件突顯了負責任地調校這類系統有多困難,甚至出現將 18 世紀歐洲貴族描繪為高度族群多元的失真結果。Google 隨後道歉並將該功能下線,也再次顯示在歷史真實性與多元呈現之間取得平衡的挑戰。
偏見不只存在於人口結構層面。AI 藝術的輸出往往傾向某些美學:精緻、商業化、符合主流審美。相較之下,實驗性、前衛,甚至刻意醜陋的藝術風格較少出現,因為它們在訓練資料中本就稀少,也較少被回饋與獎勵。從這個角度看,AI 即使在技術上極為激進,在藝術取向上卻可能相當保守。
現況(2024–2025)
現況一覽
截至 2024 年底至 2025 年初,AI 藝術領域已逐漸成熟,但整體生態仍處於高度動盪之中:
DALL E 3(整合於 ChatGPT Plus)大幅提升了提示詞的理解能力。你現在可以直接「對話式」描述想要的畫面,AI 對細節與語境的掌握也更加精準。
Midjourney V6 將美學品質再推升一個層級,文字呈現更出色(仍非完美),風格也更好掌控。
Stable Diffusion XL 及其後續發展仍在持續進化,開源社群不斷推出各式專用模型,從動漫風格、寫實影像到特定藝術流派,幾乎涵蓋所有創作需求。
Adobe Firefly 主打「負責任的 AI」路線,僅使用 Adobe Stock 圖庫與公有領域內容進行訓練,並內建商業授權機制。雖然整體能力不及 Stable Diffusion,但在商業使用上具備更高的法律安全性。
影片生成:下一個前沿
文字生成圖片只是起點。2024 年,AI 影片生成迎來實質性的重大進展:
Runway Gen 2 與 Pika 已能從文字或圖片生成短影片片段。整體品質仍不穩定,物件有時會不自然變形、物理效果也略顯怪異,但每個月都在持續進步。
OpenAI's Sora(於 2024 年 2 月公布,僅限有限釋出)展示了長達一分鐘、具備高度寫實感且敘事連貫的影片生成能力。示範影片令人瞠目結舌;同時也讓不少人感到不安——在 AI 能從文字生成逼真影片之前,深偽問題其實早已存在。
3D 與更多可能
AI 藝術正從平面圖像,持續拓展到更多元的形式:
Point E 與 Shap E(OpenAI)可透過文字提示直接生成 3D 模型。目前成品品質仍有限,但發展方向已相當明確。
NeRF(Neural Radiance Fields) 技術能從 2D 影像生成 3D 場景,為電影製作、遊戲開發到建築視覺化等領域帶來廣泛應用潛力。
音樂、文字與多模態
AI 音樂生成(Suno、Udio)在 2024 年已達到「相當不錯」的水準。AI 尚未取代音樂人,但讓功能性背景音樂的製作變得更快速、更容易,也更具成本效益。
多模態模型(具備視覺能力的 GPT‑4、Gemini)不只能理解與分析影像,還能生成相關文字,再依文字描述產出全新的影像。文字 AI 與影像 AI 之間的界線,正快速模糊與融合。
接下來會發生什麼?趨勢預測與未來想像
近期(2025–2027)
可能:
- 影片生成技術邁向主流實用階段
- 角色一致性生成(同一人物可跨多張圖片穩定呈現)變得可靠
- 在持續進行的訴訟推動下,著作權相關法規逐漸明朗
- 產業加速整併,小型團隊被併購或退出市場
- 反彈聲浪升高,部分平台與客戶開始禁止使用 AI 藝術
可能性:
- 視訊通話或直播中即時生成影片內容
- AI 藝術成為專業創作流程中的標準工具
- 「人類親手創作認證」藝術作為高端類別興起
- 大型博物館推出 AI 藝術史主題展覽(不再只是單一裝置)
中期(2027–2030)
合理推測:
- 文字、影像、影片、3D 與音訊生成整合於單一模型之中
- 以個人藝術風格訓練的客製化 AI 模型逐漸普及
- 透過頭戴式裝置整合 AR/VR,讓 AI 藝術走入實體空間
- 圍繞訓練資料的法律框架逐步成形(可能仍充滿爭議與妥協)
- 原生於 AI 的全新藝術流派出現,而非前 AI 時代風格的延伸或改編
長期來看:關鍵大哉問
AI 會超越人類的創造力嗎?這個問題本身就問錯了——兩者本來就不是同一件事。
人類藝術家會被淘汰嗎?可能性不高。隨著 AI 快速產出大量「輕而易舉」的內容,市場對真正具有人類情感與創作痕跡的「人味作品」需求,反而有機會持續升高。
AI 生成的藝術作品究竟歸誰所有?目前仍在法院中持續攻防。依照現行美國著作權法,由於缺乏「人類作者」,AI 生成作品不屬於任何人;但這項規範未來勢必會改變。
當 AI 以藝術家的作品作為訓練資料時,我們該如何回饋創作者?這個問題的價值以十億美元計,毫不誇張。可能的方向包括:授權費、按使用次數計費的微支付機制,或是類似音樂產業的強制授權制度——但目前都還沒有任何一種真正大規模落地。
是否應該設立「AI 禁用區」?有人主張,某些領域(如兒童讀物、紀念作品、法律證據)應保留給人類創作者;也有人認為這是現代版的反科技恐懼。相關爭論仍在持續中。
從歷史汲取的啟示
回顧超過 50 年的 AI 藝術發展史,我們可以清楚看見幾個關鍵脈絡逐漸浮現:
- 工具不斷走向平民化。AARON 需要程式設計能力;GAN 需要機器學習背景;而現代工具,只要有一個 Discord 帳號就能上手。每一代技術,都比上一代更容易被使用。
- 最初的炒作總是大於現實。每一次突破,都伴隨著「藝術已死」的宣告。但藝術從未消失,它只是不斷演化。
- 法律與倫理框架永遠追不上技術發展。我們至今仍在爭論三年前就已落地的技術所帶來的版權問題。法律走得慢,科技不會等。
- 對於工作被取代的擔憂,往往既合理卻不完整。沒錯,有些職位會消失;但新的角色也會出現。轉型期總是痛苦的,尤其是身處其中的人。
- 藝術會繼續存在。攝影沒有殺死繪畫,數位工具沒有終結傳統媒材,AI 也不會消滅人類的創造力。但它將改變我們如何創作、為何創作,以及創作什麼。
結語:書寫下一個篇章
從 1973 年 Harold Cohen 細心編寫程式開始,到今日數以百萬計的人在幾秒內生成影像,AI 藝術的歷史,本質上是一段關於人類創造力與運算能力之間關係不斷演變的故事。
我們現在面臨的問題,已不再主要是技術層面的——技術本身已經可行,而且進步飛快。真正需要回答的,是關於人的問題:
- 我們該如何確保 AI 是放大人類創造力,而不是取而代之?
- 對於讓 AI 得以存在的藝術家,我們該如何給予公平的回饋與報酬?
- 在這個全新的創作生態中,誰能參與,又誰被排除在外?
- 創作之中,有哪些部分是我們希望永遠只屬於人類的?
- 在科技快速轉型的過程中,我們要如何守住藝術創作者的職涯與生計?
這些問題沒有簡單答案,需要藝術家、技術開發者、企業、政策制定者,以及大眾之間不斷協商與對話。AI 藝術的歷史尚未寫完——而我們正身處其中,親歷最關鍵、也最具影響力的一個篇章。
可以確定的是,忽視 AI 並不會讓它消失,假裝它沒有帶來真實挑戰也無濟於事。真正可行的前進方式,是積極面對——誠實看待問題、對各種可能性保持開放,並且堅持公平與責任。
至於 AI 是否真的能具備創造力,也許我們問錯了問題。創造力不是非有即無的二元屬性;它存在於光譜之中,發生在協作裡,也誕生於意想不到的組合。若說 AI 藝術的前 50 年帶給我們什麼啟示,那就是:創造力比我們想像的更廣闊、更奇異。而人類,無論好壞,似乎都決心與它共享。
下一個篇章正於此刻書寫中。邀請你以深思熟慮的方式參與其中。