L’histoire complète de l’art IA : d’AARON à Midjourney (1973–2025)
Dernière mise à jour: 2026-01-22 18:07:34

Comment l’intelligence artificielle est passée de simple curiosité académique à véritable révolution artistique — et pourquoi c’est important
Ce guide retrace l’histoire de l’art IA, des premiers systèmes à base de règles jusqu’aux modèles de diffusion actuels, pour montrer comment chaque avancée a transformé les possibilités offertes aux artistes.
Quand un robot a vendu une œuvre d’art pour près d’un demi-million de dollars
En octobre 2018, un événement inédit se produit chez Christie's, à New York. Un portrait légèrement flou, évoquant vaguement la peinture européenne du XVIIIe siècle, est adjugé pour 432 500 dollars. L’acheteur ? Un collectionneur anonyme. Le vendeur ? Le collectif français Obvious. L’artiste ? Un algorithme.
"Portrait d’Edmond de Belamy" n’a pas été peint par une main humaine. Il a été généré par un réseau antagoniste génératif (GAN), entraîné sur 15 000 portraits historiques. La signature dans le coin n’était pas un nom, mais une formule mathématique : "min max Ex[log(D(x))] + Ez[log(1 D(G(z)))]."
Le monde de l’art s’est divisé. Pour certains, c’était un tournant historique. Pour d’autres, un simple coup marketing — voire un scandale — surtout lorsqu’il est apparu que le collectif avait utilisé du code open source sans créditer correctement son auteur, le programmeur Robbie Barrat. Mais au-delà de la polémique, une chose est devenue évidente : l’art généré par l’IA était bel et bien entré en scène, et il n’était plus possible de refermer la boîte de Pandore.
Mais voici ce que la plupart des gens ignorent : la vente aux enchères de 2018 n’a pas marqué le début de l’histoire de l’art IA. On en est même très loin. L’histoire commence en réalité 45 ans plus tôt, dans le laboratoire informatique d’une université, avec un peintre britannique qui a estimé que son pinceau ne le poussait plus assez loin.
Chronologie express :
Années 1960 : Les premières expérimentations en art informatique et algorithmique posent les bases
1973 : Harold Cohen lance AARON
2015 : DeepDream et les premières expériences de transfert de style deviennent virales
2014–2018 : les GANs font un bond en réalisme visuel ; l’art IA fait son entrée dans les galeries et les maisons de vente
2021 : CLIP ouvre la voie à la compréhension texte-image
2022 : Les modèles de diffusion + Midjourney / DALL·E / Stable Diffusion propulsent l’art IA dans le grand public
2023–2025 : droits d’auteur, consentement des jeux de données, outils de traçabilité : les débats réglementaires s’intensifient
Le pionnier malgré lui : comment un peintre a créé le premier artiste IA
Harold Cohen et AARON (1973–2016)

En 1968, Harold Cohen est au sommet de sa carrière. Il représente la Grande-Bretagne à la Biennale de Venise. Ses peintures abstraites sont exposées dans des galeries renommées. Pourtant, un doute l’habite. Comme il le dira plus tard : « Il se passe peut-être des choses plus intéressantes en dehors de mon atelier qu’à l’intérieur. »
Cohen enseignait à l’UC San Diego lorsqu’il a découvert l’informatique. Non pas comme un simple outil pour numériser son travail existant, mais comme quelque chose de bien plus fondamental : un ordinateur pouvait-il, en soi, créer de l’art ? Non pas reproduire, ni copier, mais réellement créer ?
Le résultat fut AARON, un nom choisi en partie en référence au frère de Moïse dans l’Exode. Lorsque Cohen le présente pour la première fois à l’UC Berkeley en 1974, AARON ne sait produire que des motifs abstraits. Mais c’est là que réside sa révolution : il ne se contente pas d’exécuter des instructions prédéfinies. Cohen l’a doté de règles sur la composition, la fermeture des formes et des concepts plastiques qu’il maîtrisait en tant que peintre ; à l’intérieur de ce cadre, AARON prenait ses propres décisions.
Voyez-le ainsi : Cohen a enseigné à AARON la grammaire du langage visuel, mais AARON écrivait ses propres phrases.
Dès les années 1980, AARON produisait des images clairement reconnaissables : figures humaines, plantes, scènes d’intérieur. Cohen le laissait alors s’exprimer à l’aide d’un bras de dessin robotisé (conçu avec des collaborateurs dans des laboratoires universitaires, tandis qu’il explorait la manière dont le code pouvait « dessiner » dans le monde physique). Le système réalisait ainsi des dessins d’une grande richesse. Chacun était unique. Tous portaient indéniablement la signature d’AARON, sans jamais se ressembler.
Ce qui est fascinant, c’est que Cohen ne pouvait jamais anticiper entièrement ce qu’AARON allait produire. Certaines instructions de programmation donnaient naissance à des formes qu’il n’avait pas imaginées. La machine lui révélait des possibles enfouis dans son propre système artistique, des pistes qu’il n’avait jamais perçues lui-même.
AARON n’a cessé d’évoluer pendant plus de 40 ans. La version de 2001 produisait des scènes colorées peuplées de figures et de plantes. Celle de 2007 (« Gijon ») générait des paysages denses, presque tropicaux. À la mort de Cohen en 2016, il laissait derrière lui non seulement des milliers d’œuvres, mais aussi une question fondamentale : si AARON surprenait son propre créateur par des compositions inédites, pouvait-on parler de créativité ?
De grandes institutions, dont le Whitney, ont exposé des œuvres et des documents liés à AARON de Cohen, soulignant son importance dans l’histoire de l’art numérique. On peut encore voir AARON générer des images aujourd’hui, même si tout ce qui a été créé après la mort de Cohen est considéré, de manière controversée, comme inauthentique.
Avant AARON : l’art génératif et les premières expérimentations informatiques (années 1960)
Bien avant les modèles actuels, des artistes utilisaient déjà des algorithmes pour générer des formes visuelles. Dès les années 1960, les premiers dessins réalisés avec des traceurs informatiques et l’« art génératif » fondé sur des règles ont posé un principe clé qui définit encore l’art IA aujourd’hui : l’artiste conçoit un système, et ce système produit des variations qui dépassent la simple répétition manuelle.
Les décennies discrètes : l’art IA avant l’engouement (années 1980–2000)
Pendant que Cohen développait AARON, d’autres artistes exploraient eux aussi la créativité computationnelle — mais ces travaux restaient largement confidentiels, cantonnés aux cercles universitaires.
Karl Sims est sans doute la figure la plus connue de cette période — du moins dans les cercles de l’art numérique. Dans les années 1980, au MIT Media Lab, puis chez Thinking Machines (une entreprise spécialisée dans les supercalculateurs), Sims a créé des animations 3D basées sur le principe de « l’évolution artificielle ». Son approche : générer des formes 3D aléatoires, les faire muter, sélectionner les plus intéressantes, puis recommencer. Une véritable sélection naturelle appliquée à des créatures numériques.
Son œuvre « Panspermia » (1991) et « Liquid Selves » (1992) ont remporté les plus hautes distinctions à Ars Electronica, le prestigieux festival des arts numériques. Si vous avez déjà vu ces animations 3D hypnotiques, aux formes organiques qui ne ressemblent à rien de connu dans la nature mais semblent pourtant presque vivantes, c’est à Sims que l’on doit cette esthétique pionnière.
Scott Draves a adopté une approche différente avec « Electric Sheep » (1999). Oui, c’est un économiseur d’écran — vous vous souvenez ? — mais un économiseur d’écran qui apprend. Distribué sur des milliers d’ordinateurs, il génère des animations fractales évolutives appelées « sheep ». Quand les spectateurs votent pour les motifs qu’ils préfèrent, le système « reproduit » davantage de ces patterns. Le projet fonctionne encore aujourd’hui. Allez sur electricsheep.org pour le voir en action.
À cette époque, l’expression « art génératif » s’impose. Les artistes écrivent du code pour définir des règles et des paramètres, puis laissent les algorithmes créer à l’intérieur de ce cadre. Lancé en 2001, Processing — un langage de programmation conçu spécialement pour les artistes — rend cette approche beaucoup plus accessible.
Mais voilà le hic : pour la plupart des gens, tout cela ne ressemblait pas à de l’« IA ». C’étaient certes de beaux projets d’art numérique, mais ils ne semblaient pas vraiment intelligents. Ils ne comprenaient pas ce qu’ils produisaient. Ils appliquaient des règles, aussi complexes soient-elles.
Tout était sur le point de changer.
Le deep learning change la donne (2012–2015)
Au début des années 2010, un tournant décisif s’est opéré. Trois facteurs se sont rejoints :
D’abord, les GPU (graphics processing units) sont devenus suffisamment puissants pour entraîner des réseaux neuronaux de très grande taille. Ironie de l’histoire : des puces conçues pour le jeu vidéo ont rendu possibles des avancées majeures en IA.
Deuxième élément clé : l’arrivée de jeux de données massifs. Lancé en 2009, ImageNet rassemble des millions d’images annotées. Pour la première fois, les réseaux neuronaux disposaient d’assez d’exemples pour apprendre de véritables motifs.
Troisièmement, les algorithmes de deep learning ont connu un bond spectaculaire. En 2012, les modèles d’apprentissage profond ont pulvérisé les benchmarks de reconnaissance d’images (popularisés par ImageNet), reléguant les approches classiques de vision par ordinateur au second plan. Un déclic pour les chercheurs : en rendant les réseaux neuronaux suffisamment profonds (avec de nombreuses couches), en leur fournissant assez de données et de puissance de calcul, ils commencent à produire des résultats étonnamment « intelligents ».
Pour le monde de l’art, les implications ont été considérables.
Le moment Deep Dream (2015)
En juin 2015, l’ingénieur de Google Alexander Mordvintsev publie quelque chose d’assez déroutant. Il travaillait sur la visualisation de la manière dont les réseaux neuronaux reconnaissent les objets. L’idée : si un réseau est entraîné à reconnaître des chiens, que se passe-t-il si l’on inverse le processus et qu’on lui demande d’amplifier tout ce qui ressemble à un chien dans une image ?
Les résultats étaient déroutants. Psychédéliques. Presque hallucinatoires. Donnez-lui une photo de nuages : le réseau y détectait partout des visages de chiens, des yeux, des éléments architecturaux, puis les amplifiait jusqu’à créer des paysages surréalistes. La communauté artistique s’est enflammée.
Google l’a baptisé DeepDream (officiellement « Inceptionism »). En quelques semaines, des artistes ont commencé à créer de véritables galeries d’œuvres DeepDream. Une esthétique à part entière est née : des images saturées d’yeux et de motifs organiques tourbillonnants. Aujourd’hui encore, une image DeepDream se reconnaît au premier coup d’œil.
Ce qui lui a donné une portée culturelle, ce n’était pas seulement le rendu visuel. C’était cette prise de conscience : voilà ce que voit un réseau de neurones quand il observe le monde. Il ne voit pas comme nous. Il perçoit des motifs, des corrélations, des relations statistiques. Et, une fois matérialisés en images, ces motifs ressemblent à des rêves fiévreux.
C’était totalement déroutant. Et le public a adoré.
Transfert de style : les réseaux neuronaux comme artistes (2015–2016)
À la même époque, des chercheurs ont découvert comment utiliser les réseaux neuronaux pour le « style transfer » : appliquer le style d’une image à une autre. Envie de voir votre photo réinterprétée dans le style de La Nuit étoilée de Van Gogh ? Quelques secondes suffisent.
L’article scientifique était ardu (Gatys et al., 2015), mais les applications qui en découlaient se sont multipliées. En 2016, Prisma devient un phénomène viral. Du jour au lendemain, n’importe qui, avec un simple smartphone, peut créer de l’« art » aux allures de tableaux célèbres.
Des critiques ont souligné qu’il ne s’agissait pas vraiment de créer un art inédit, mais plutôt d’une imitation algorithmique. En revanche, cela démontrait quelque chose de nouveau : les réseaux neuronaux étaient capables de comprendre un style artistique avec suffisamment de finesse pour le reproduire.
GANs : la technologie qui a marqué un tournant (2014–2020)
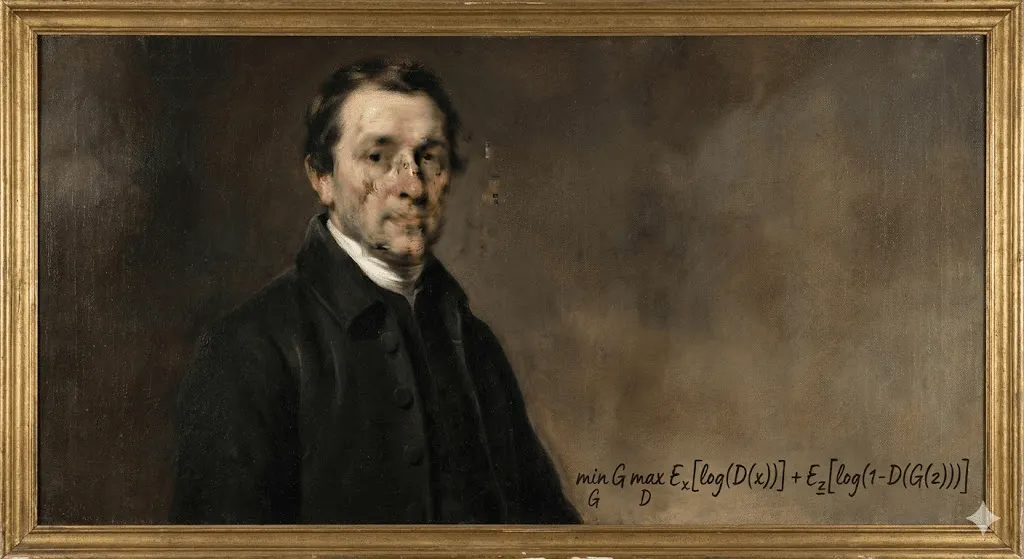
Pour les artistes, les GANs ont été décisifs : ils ont rendu le « style » apprenable à partir des données, permettant d’explorer un univers visuel sans avoir à coder manuellement chaque règle.
Comment fonctionnent les GAN (sans les maths)
En 2014, Ian Goodfellow, alors doctorant à l’Université de Montréal, présente les Generative Adversarial Networks dans un article appelé à devenir l’un des plus cités de l’histoire du machine learning. Yann LeCun, figure fondatrice du deep learning, qualifiera les GAN de « l’idée la plus intéressante en machine learning depuis dix ans ».
Voici l’idée : imaginez deux réseaux neuronaux qui jouent l’un contre l’autre.
Réseau 1 (le générateur) : Tente de créer des images factices qui paraissent réelles.
Réseau 2 (le Discriminateur) : Cherche à distinguer les images générées des images réelles.
Au départ, le Générateur est mauvais et ne produit qu’un bruit aléatoire. Le Discriminateur repère immédiatement les faux. Mais c’est là que tout devient intéressant : le Générateur apprend de ses échecs. Il s’ajuste pour tromper le Discriminateur. Celui-ci affine alors sa capacité à détecter les faux. Le Générateur s’adapte à nouveau. Un va-et-vient répété des milliers de fois.
Avec le temps, le Générateur devient si performant que même le Discriminateur n’arrive plus à distinguer le faux du réel. À ce stade, le réseau neuronal est capable de créer, à partir de rien, des images véritablement crédibles.
La véritable révolution : les GAN n’ont plus besoin de données annotées par des humains pour chaque résultat possible. Ils apprennent la distribution statistique sous-jacente de ce sur quoi ils sont entraînés — visages, paysages, n’importe quel type d’images — et peuvent ensuite en générer une infinité de variations.
Des visages étranges à un art convaincant (2015–2018)
Les premiers résultats des GAN étaient… disons « expérimentaux ». Si vous vous souvenez de ces visages générés par IA vers 2015 — déformés, inquiétants, tout droit sortis de l’uncanny valley — c’étaient des GAN de première génération. Les chercheurs les partageaient comme preuve de concept, et ils sont rapidement devenus des mèmes.
Mais la technologie a progressé à grande vitesse. Dès 2017, le Progressive GAN de NVIDIA était capable de générer des visages en 1024×1024 pratiquement indiscernables de photographies. En 2018, StyleGAN a franchi un nouveau cap : une résolution encore plus élevée, avec en plus un contrôle fin sur différents aspects des images.
Les artistes se sont mis à expérimenter. Mario Klingemann, artiste allemand, a créé « Memories of Passersby I » (2018), une installation composée de deux écrans diffusant des portraits générés en continu. Ils défilent comme des souvenirs, sans jamais se répéter. L’œuvre a été vendue chez Sotheby’s pour £40,000.
Helena Sarin a adopté une approche différente : entraîner des GANs à partir de ses propres dessins plutôt que de photographies. Elle conserve ainsi la maîtrise artistique tout en tirant parti de la puissance générative de l’IA. Sa série « AI Candy Store » affiche une esthétique distinctive, immédiatement identifiable comme de l’IA, avec sa signature personnelle pleinement intégrée.
Robbie Barrat, alors lycéen, entraîne des GAN sur des œuvres d’art classiques et partage son code en open source sur GitHub. (C’est ce code qu’Obvious utilisera plus tard pour la vente chez Christie’s, déclenchant une controverse sur l’attribution et la paternité artistique.)
The Next Rembrandt (2016)
Avant le coup d’éclat aux enchères d’Obvious, il y a eu « The Next Rembrandt » (2016), un projet marketing porté par la banque ING et plusieurs institutions néerlandaises. Ils ont numérisé les 346 tableaux de Rembrandt, entraîné un algorithme à comprendre son style, puis généré un « nouveau » portrait de Rembrandt.
Ce n’était pas à proprement parler un GAN, mais l’idée était proche : une IA peut-elle créer dans le style d’un artiste précis ? Le projet a bénéficié d’une couverture médiatique massive. Les critiques ont salué la prouesse technique, tout en s’interrogeant : s’agissait-il réellement d’art, ou simplement d’un pastiche sophistiqué ?
Elle a soulevé des questions qui nous travaillent encore aujourd’hui : s’entraîner sur l’œuvre d’un artiste, est-ce un hommage respectueux ou une appropriation computationnelle ? À partir de quand l’inspiration devient-elle du pillage ?
L’explosion : quand l’art IA est entré dans la culture populaire (2022–aujourd’hui)
CLIP : apprendre à l’IA à comprendre le texte et les images (2021)
La percée suivante arrive en janvier 2021 avec OpenAI : CLIP (Contrastive Language Image Pre training). Les détails techniques sont complexes, mais l’impact est clair : CLIP est capable de comprendre la relation entre le texte et les images.
Les systèmes précédents nécessitaient des données étiquetées : « ceci est un chat », « ceci est un chien ». CLIP, lui, a appris à partir de 400 millions de paires image‑texte collectées sur Internet. Il a compris que certains mots sont régulièrement associés à des caractéristiques visuelles précises. Résultat : un « espace » commun où textes et images peuvent être comparés.
Pourquoi c’était décisif : en combinant CLIP avec un modèle génératif, il devient possible de créer des images à partir de descriptions textuelles. Tapez « un astronaute chevauchant un cheval », et le système comprend immédiatement à quoi cela doit ressembler.
Les artistes ont rapidement détourné CLIP pour l’intégrer à leurs workflows. En l’associant à des GAN ou à d’autres générateurs, ils pouvaient piloter la création d’images à partir du langage. C’était encore maladroit, mais ça fonctionnait.
La révolution de 2022 : DALL E 2, Midjourney, Stable Diffusion

Puis 2022 est arrivé : tout a basculé d’un coup.
DALL E 2 (OpenAI, avril 2022) a combiné CLIP et les modèles de diffusion (nous y revenons juste après) pour générer des images de haute qualité, cohérentes, à partir de simples descriptions textuelles. L’accès anticipé a été réservé à une sélection d’artistes et de chercheurs. La liste d’attente a rapidement dépassé le million de personnes. Les images partagées par OpenAI étaient d’une créativité saisissante, cohérentes, souvent magnifiques.
Midjourney (Midjourney Inc., juillet 2022) a choisi une voie différente : une approche communautaire, centrée sur Discord et résolument tournée vers l’esthétique. Très vite, un style reconnaissable s’est imposé : pictural, dramatique, souvent fantastique. Les artistes s’y sont rués. Le serveur Discord est devenu l’une des communautés créatives les plus actives du web.
Stable Diffusion (Stability AI, août 2022) a changé la donne en matière d’accessibilité. Contrairement à DALL E 2 (uniquement via le web, accès contrôlé) ou à Midjourney (sur abonnement), Stable Diffusion était open source. Tout le monde pouvait le télécharger, l’exécuter en local et le modifier.
En quelques mois à peine, tout un écosystème a émergé : interfaces web, applications mobiles, plugins pour Photoshop, des centaines de modèles personnalisés entraînés pour des styles précis. Une explosion sans précédent.
Fin 2022, les réseaux sociaux ont été envahis par l’art généré par l’IA. Le « prompt engineering » est devenu une compétence à part entière. Les utilisateurs échangeaient astuces et recettes pour obtenir de meilleurs résultats. Et les débats faisaient rage : révolution démocratique de la création… ou menace pour l’art tel qu’on le connaît ?
Modèles de diffusion : les coulisses de la magie
Alors, qu’est-ce qu’un modèle de diffusion ? Le principe vient directement de la physique, et plus précisément de la manière dont des particules se diffusent à travers un milieu.
Le processus d’entraînement :
- Partir d’une image réelle
- Ajouter progressivement du bruit jusqu’à obtenir un bruit totalement aléatoire (diffusion avant)
- Entraîner un réseau neuronal à inverser le processus et supprimer le bruit (diffusion inverse)
Le processus de génération : on part d’un bruit aléatoire, on applique le processus de diffusion inverse, et l’on obtient progressivement une image cohérente. Le conditionnement par le texte (via CLIP) oriente le type d’image qui prend forme.
Pourquoi les modèles de diffusion ont pris le dessus sur les GAN pour cet usage : ils sont plus stables, plus simples à entraîner et bien meilleurs pour interpréter des instructions textuelles. Les GAN restent utilisés dans certains cas, mais ce sont clairement les modèles de diffusion qui ont porté l’explosion de 2022.
Parenthèse technique : l’article clé est « Denoising Diffusion Probabilistic Models » (Ho et al., 2020), même si des travaux antérieurs de Sohl-Dickstein et al. (2015) en ont posé les bases. Si vous voulez vraiment comprendre le fonctionnement en profondeur, ces publications sont de bons points de départ — mais attention, le niveau mathématique est élevé.
En chiffres
- Début 2023, ces outils avaient déjà conquis des millions d’utilisateurs, et les images générées par l’IA inondaient les réseaux sociaux.
- DALL E : plus de 3 millions d’utilisateurs (liste d’attente levée)
- Stable Diffusion : impossible à chiffrer (open source, distribué), mais les statistiques GitHub laissent penser à des millions
Des centaines de millions d’images ont été générées par l’IA. Des entreprises entières ont émergé pour proposer des services d’art IA. Les banques d’images ont dû revoir en urgence leurs règles. Pendant ce temps, de nombreux artistes traditionnels assistaient, déconcertés, à l’apparition d’un nouveau métier : « artiste IA ».
L’autre visage de l’art IA : les usages académiques
Alors que l’attention se portait surtout sur les générateurs texte‑vers‑image, des chercheurs utilisaient discrètement l’IA pour transformer en profondeur l’étude de l’histoire de l’art. Cette facette de l’art IA est moins médiatisée, mais elle est sans doute bien plus déterminante sur le plan académique.
Vision par ordinateur pour l’attribution et l’analyse
Les historiens de l’art ont toujours peiné à attribuer une œuvre à son auteur. Aujourd’hui, les réseaux neuronaux leur apportent un nouvel appui.
Le Rutgers Art & AI Lab (dirigé par Ahmed Elgammal) a mis au point des systèmes capables d’analyser les coups de pinceau, la composition et les marqueurs stylistiques afin d’identifier des artistes ou de détecter des faux. En 2017, lors de tests contrôlés, ces modèles ont attribué correctement des œuvres non étiquetées à leurs auteurs avec un taux de précision supérieur à 90 %.
Reconstitution d’œuvres perdues : Des réseaux neuronaux entraînés sur les œuvres connues d’un artiste peuvent générer des reconstitutions plausibles de pièces disparues ou endommagées. L’exemple le plus célèbre : l’utilisation de l’IA pour extrapoler La Ronde de nuit de Rembrandt, mutilée en 1715, afin d’imaginer à quoi pouvaient ressembler les parties manquantes. (Même si les historiens de l’art en débattent, il s’agit d’une spéculation éclairée, pas d’une restauration.)
Herculaneum Scrolls: En 2023, des chercheurs en informatique ont utilisé le machine learning pour lire des textes provenant de rouleaux antiques carbonisés lors de l’éruption du Vésuve en 79 apr. J.-C. Trop fragiles pour être déroulés, ces rouleaux ont pu être analysés grâce à des scanners CT combinés à des réseaux neuronaux entraînés capables de détecter les traces d’encre. L’IA permet ainsi, pour la première fois depuis 2 000 ans, de redonner accès à des textes anciens. (Source : Nature, 2023)
Musées et IA
De grandes institutions ont exploré l’IA de manière fascinante :
Le Met a expérimenté la visualisation de collections assistée par IA, en cartographiant à grande échelle ses archives muséales dans un « espace latent » afin de révéler des liens inattendus entre les œuvres. : Collaboration entre le Metropolitan Museum, le MIT et l’artiste Refik Anadol. Des réseaux neuronaux ont été entraînés sur l’intégralité de la collection du Met (plus de 375 000 œuvres), puis ont permis de visualiser cet « espace latent » — le territoire conceptuel entre différents types d’objets. Cette approche a fait émerger des rapprochements surprenants : une aiguière perse antique et un vase du XIXe siècle peuvent ainsi se révéler conceptuellement proches, d’une manière que les conservateurs humains n’auraient jamais identifiée.
Les expérimentations IA du MoMA : « Unsupervised » de Refik Anadol (2022–2023) s’appuyait sur un modèle de machine learning entraîné à partir des collections du MoMA pour générer des projections fluides et oniriques dans le hall du musée. Les puristes de l’art étaient partagés : certains y voyaient un gadget, d’autres une nouvelle manière d’explorer et de vivre les archives muséales.
Le projet Transparent AI de la LMU de Munich : Dirigée par le professeur Hubertus Kohle, cette recherche développe des outils d’IA pour l’histoire de l’art capables d’expliquer leur raisonnement. Les réseaux neuronaux classiques sont de véritables « boîtes noires » : ils donnent une réponse sans dire pourquoi. Ce projet rend les décisions de l’IA compréhensibles, un enjeu clé pour leur adoption dans le monde académique. Les équipes entraînent des modèles à repérer les similarités visuelles entre œuvres et à expliciter les caractéristiques qui fondent leurs conclusions.
Ces applications ne produisent pas de nouvelles œuvres, mais elles transforment en profondeur notre manière d’étudier l’histoire de l’art. Un impact sans doute plus durable que n’importe quelle image générée.
La controverse : droits d’auteur, éthique et avenir de la créativité

C’est ici que le débat s’enflamme. Les avancées techniques sont impressionnantes, mais les enjeux éthiques sont… complexes.
La bataille du droit d’auteur
Le problème de fond : les modèles d’art IA sont entraînés sur des milliards d’images collectées sur Internet. Beaucoup sont protégées par le droit d’auteur. Les artistes n’ont pas été consultés. Ils n’ont pas été rémunérés. Et aujourd’hui, des systèmes entraînés sur leurs œuvres peuvent générer en quelques secondes des images « dans leur style ».
Principales poursuites judiciaires intentées :
Getty Images vs. Stability AI (janvier 2023) : Getty accuse Stability d’avoir aspiré des millions de ses images pour entraîner Stable Diffusion. L’entreprise affirme disposer de preuves, certaines images générées affichant encore des fragments de filigranes Getty, laissant clairement apparaître leur provenance.
Action collective (class action) intentée par des artistes contre Midjourney, Stable Diffusion et DeviantArt (janvier 2023) : menée par les artistes Sarah Andersen, Kelly McKernan et Karla Ortiz. Elle dénonce une violation massive du droit d’auteur. L’affaire est toujours en cours fin 2024, et les experts juridiques sont partagés quant à l’issue probable.
La question juridique : l’entraînement sur des images protégées relève-t-il de l’usage loyal — comme un étudiant qui apprend en étudiant des œuvres existantes — ou constitue-t-il une violation du droit d’auteur, en utilisant des créations sans autorisation à des fins commerciales ?
Les tribunaux n’ont pas encore tranché. Leur décision façonnera l’ensemble de l’industrie.
Réactions des artistes : la riposte
Les artistes n’attendent pas les tribunaux. Ils développent leurs propres contre-mesures techniques.
Glaze (University of Chicago, 2023) : logiciel qui modifie subtilement les œuvres numériques de manière imperceptible pour l’œil humain, mais qui « empoisonne » l’entraînement des IA. Lorsqu’un modèle s’entraîne sur des images protégées par Glaze, ses résultats deviennent déformés. Une sorte de filigrane actif qui ne cherche pas à identifier, mais à perturber.
Nightshade (Université de Chicago, 2023) : plus agressif que Glaze. Il ne se contente pas de protéger l’image « Nightshadée » : il dégrade activement les performances globales du modèle. Téléversez suffisamment d’images Nightshade étiquetées « chien » mais montrant en réalité des chats, et le modèle finit par ne plus savoir à quoi ressemble un chien.
Ces outils font débat. Les chercheurs en IA y voient un sabotage préjudiciable. Les artistes parlent d’autodéfense. Les deux points de vue se défendent.
La proposition « Do Not Train » : Des artistes et défenseurs des droits ont proposé des balises de métadonnées indiquant qu’une œuvre ne peut pas être utilisée pour l’entraînement des IA. Certaines plateformes (DeviantArt, Shutterstock) ont mis en place des systèmes d’opt‑out. Mais dans les faits, l’application reste très limitée : les entreprises d’IA peuvent simplement ignorer ces balises — et beaucoup le font.
Le débat sur la créativité
Au-delà du droit d’auteur se pose une question philosophique : l’art généré par l’IA est-il vraiment de l’art ?
Ce que ce n’est pas :
- Manque d’intention humaine et de profondeur émotionnelle
- Produit par recombinaison d’œuvres existantes, sans véritable création originale
- Ne demande aucune compétence : il suffit de taper une requête
- Remet en cause ce qui fait la valeur de l’art : la créativité humaine et l’effort
Arguments en faveur :
- Les outils ne rendent pas l’art moins légitime (la photographie n’a pas mis fin à la peinture)
- Le prompt engineering et la curation sont des compétences à part entière
- Les humains guident l’IA et prennent les décisions créatives
- Ouvre de nouvelles formes d’expression auparavant impossibles
Mon point de vue : le débat n’est pas le bon. C’est comme se demander en 1850 si la photographie est un art. Bien sûr que l’IA peut créer de l’art — on l’a déjà vu. Les vraies questions sont ailleurs : quel type de relation voulons-nous entre la créativité humaine et la machine ? Qui en bénéficie ? Qu’est-ce qui se perd ? Qu’est-ce qui s’y gagne ?
La réalité du remplacement des emplois
Ce n’est pas une question théorique. Des personnes bien réelles perdent leur emploi.
Une enquête menée en 2023 par la Concept Art Association a révélé :
- 73 % des concept artists déclarent une baisse des opportunités professionnelles
- 62 % ont perdu des missions freelance au profit de l’IA
- Les postes de niveau débutant sont ceux qui disparaissent le plus rapidement
Des entreprises utilisent l’IA pour le travail de concept en amont, les storyboards ou les décors — exactement les missions autrefois confiées aux artistes en début de carrière. Certains défenseurs estiment que cela ne diffère pas du remplacement des techniques traditionnelles par des outils numériques. Mais la vitesse du changement est sans précédent, et la colère des artistes concernés est plus que compréhensible.
Parallèlement, de nouveaux métiers émergent : directeurs artistiques IA, prompt engineers, spécialistes des workflows hybrides humain‑IA. Reste à savoir s’ils compenseront les emplois perdus à l’identique.
Le problème des biais
Les modèles d’art IA héritent des biais présents dans leurs données d’entraînement. Demandez « un CEO » et vous obtiendrez surtout des hommes blancs. « Une infirmière » renverra majoritairement des femmes. « Une personne belle » penchera fortement vers des visages jeunes, blancs et correspondant aux canons de beauté conventionnels.
En 2024, Google a tenté de corriger le tir avec Gemini en augmentant la diversité dans les images historiques, mais a largement surcorrigé, déclenchant une controverse sur l’équilibre entre exactitude historique, représentation et sécurité. L’épisode a mis en lumière la difficulté de régler ces systèmes de manière responsable — jusqu’à produire une noblesse européenne du XVIIIe siècle artificiellement diversifiée. Google a présenté ses excuses et retiré la fonctionnalité. L’incident a illustré à quel point il est complexe de concilier fidélité historique et représentation.
Les biais ne se limitent pas aux questions démographiques. L’art généré par l’IA privilégie souvent certaines esthétiques : des images lisses, commerciales, « jolies » au sens conventionnel. Les œuvres expérimentales, avant-gardistes ou volontairement dérangeantes apparaissent plus rarement, tout simplement parce qu’elles sont moins présentes — et moins valorisées — dans les données d’entraînement. En ce sens, l’IA peut se montrer artistiquement conservatrice, même lorsqu’elle est techniquement radicale.
Où nous en sommes aujourd’hui (2024–2025)
Le paysage actuel
Fin 2024 / début 2025, le paysage de l’art IA a gagné en maturité, tout en restant traversé par de fortes turbulences :
DALL E 3 (intégré à ChatGPT Plus) a fait un bond spectaculaire dans la compréhension des prompts. Il est désormais possible de dialoguer avec l’IA pour affiner ses idées, avec une compréhension beaucoup plus fine des nuances.
Midjourney V6 a repoussé encore plus loin la qualité esthétique, avec un rendu du texte amélioré (encore imparfait) et des styles plus faciles à maîtriser.
Stable Diffusion XL et au-delà continue d’évoluer, portée par la communauté open source qui développe des modèles spécialisés pour tout, de l’anime au photoréalisme, en passant par des styles artistiques précis.
Adobe Firefly incarne l’approche de l’« IA responsable » : un modèle entraîné uniquement sur des images Adobe Stock et des contenus du domaine public, avec des droits commerciaux intégrés. Moins puissant que Stable Diffusion, il se distingue toutefois par une sécurité juridique accrue pour les usages professionnels.
Génération vidéo : la prochaine frontière
Le texte vers image n’était qu’un début. En 2024, la génération de vidéos par l’IA a franchi un cap décisif :
Runway Gen 2 et Pika peuvent générer de courts clips vidéo à partir de texte ou d’images. La qualité reste inégale : les objets se transforment de façon peu naturelle, la physique déraille parfois, mais progresse mois après mois.
Sora d’OpenAI (annoncé en février 2024, diffusion limitée) a marqué les esprits en montrant des vidéos photoréalistes et cohérentes pouvant durer jusqu’à une minute. Les vidéos de démonstration étaient tout simplement stupéfiantes. Elles ont aussi inquiété de nombreuses personnes : les deepfakes posaient déjà problème avant même que l’IA ne soit capable de générer des vidéos crédibles à partir d’un simple texte.
La 3D et au-delà
L’art IA ne se limite plus aux images en 2D :
Point E et Shap E (OpenAI) permettent de générer des modèles 3D à partir de simples prompts textuels. La qualité reste encore limitée, mais la direction est sans équivoque.
La technologie NeRF (Neural Radiance Fields) permet de générer des scènes 3D à partir d’images 2D, avec des applications allant du cinéma au développement de jeux vidéo, en passant par la visualisation architecturale.
Musique, texte et multimodalité
En 2024, la génération musicale par IA (Suno, Udio) a atteint un niveau « plutôt convaincant ». L’IA n’a pas remplacé les musiciens, mais elle rend la production de musiques fonctionnelles et d’ambiance plus simple et plus abordable.
Les modèles multimodaux (GPT‑4 avec vision, Gemini) savent analyser des images, produire du texte à leur sujet, puis générer de nouvelles images à partir de ce texte. Les frontières entre l’IA du texte et l’IA de l’image deviennent de plus en plus floues.
Et après ? Prédictions et perspectives
À court terme (2025–2027)
Probable :
- La génération vidéo atteint un niveau d’usage grand public
- La génération de personnages cohérents (la même personne sur plusieurs images) devient fiable
- Davantage de clarté juridique sur le droit d’auteur (imposée par les contentieux en cours)
- Consolidation du secteur, avec le rachat ou la disparition de petits acteurs
- La contestation s’intensifie, certaines plateformes et certains clients interdisant l’art IA
C’est possible :
- Génération vidéo en temps réel pendant les appels vidéo ou le streaming
- L’art IA devient un outil standard dans les workflows créatifs professionnels
- Émergence de l’art « certifié fait par des humains » comme catégorie premium
- Grande exposition muséale consacrée à l’histoire de l’art IA (au-delà d’installations isolées)
Moyen terme (2027–2030)
Spéculatif mais plausible :
- La génération de texte, d’images, de vidéo, de 3D et d’audio unifiée au sein de modèles uniques
- Les modèles d’IA personnalisés, entraînés sur des styles artistiques individuels, se généralisent
- L’intégration AR/VR permet d’intégrer l’art IA dans des espaces physiques via des casques
- Des cadres juridiques instaurent des compromis (probablement complexes) autour des données d’entraînement
- De nouveaux mouvements artistiques émergent, nativement IA, et non de simples adaptations de styles pré‑IA
À long terme : les grandes questions
L’IA dépassera-t-elle la créativité humaine ? Mauvaise question : ce sont deux formes de création fondamentalement différentes.
Les artistes humains vont-ils devenir obsolètes ? Peu probable. À mesure que l’IA inonde le marché de contenus faciles à produire, la valeur — et la demande — pour des œuvres « authentiquement humaines » pourrait au contraire augmenter.
À qui appartient l’art généré par l’IA ? La question se joue encore devant les tribunaux. Le droit d’auteur américain actuel considère qu’il n’appartient à personne (absence d’auteur humain), mais cela évoluera.
Comment rémunérer les artistes dont les œuvres servent à entraîner l’IA ? C’est la question à un milliard de dollars — au sens littéral. Plusieurs pistes existent : frais de licence, micropaiements à l’usage, systèmes de licence obligatoire comme dans la musique. Mais aucune n’est encore déployée à grande échelle.
Faut-il instaurer des zones sans IA ? Pour certains, des usages précis — livres pour enfants, mémoriaux, preuves juridiques — devraient rester l’apanage de créateurs humains. D’autres y voient un réflexe néo-luddite. Le débat reste ouvert.
Les enseignements de l’histoire
Avec le recul de plus de 50 ans d’histoire de l’art IA, quelques grandes tendances se dégagent :
- Les outils se démocratisent. AARON exigeait des compétences en programmation. Les GAN demandent des connaissances en machine learning. Les outils modernes, eux, nécessitent surtout… un compte Discord. À chaque génération, l’accès devient plus simple.
- L’enthousiasme initial dépasse souvent la réalité. Chaque avancée déclenche des proclamations du type « l’art est mort ». L’art ne meurt pas. Il se transforme.
- Les cadres juridiques et éthiques peinent à suivre la technologie. Nous débattons encore de questions de droits d’auteur liées à des technologies déployées il y a trois ans. Le droit avance lentement ; la technologie, non.
- Les inquiétudes liées au remplacement sont souvent fondées, mais incomplètes. Oui, certains métiers disparaissent. Mais d’autres apparaissent. La période de transition est douloureuse, surtout pour celles et ceux qui la traversent de plein fouet.
- L’art survit. La photographie n’a pas tué la peinture. Les outils numériques n’ont pas éliminé les médias traditionnels. L’IA ne tuera pas la créativité humaine. Mais elle changera la manière dont nous créons, pourquoi nous créons, et ce que nous créons.
Conclusion : écrire le prochain chapitre
De la programmation patiente d’Harold Cohen en 1973 aux millions de personnes qui génèrent aujourd’hui des images en quelques secondes, l’histoire de l’art IA raconte avant tout l’évolution des relations entre la créativité humaine et la puissance de calcul.
Les enjeux d’aujourd’hui ne sont plus d’abord techniques : la technologie fonctionne, et elle progresse à une vitesse fulgurante. Ce sont des questions profondément humaines.
- Comment faire en sorte que l’IA amplifie la créativité humaine plutôt que de la remplacer ?
- Comment rémunérer équitablement les artistes dont le travail rend l’IA possible ?
- Qui a accès à ce nouveau paysage créatif ?
- Quelles dimensions de la créativité voulons-nous préserver comme proprement humaines ?
- Comment préserver les carrières et les moyens de subsistance des artistes pendant cette transition technologique ?
Ces questions n’ont pas de réponses simples. Elles exigent un dialogue — et des compromis — entre artistes, technologues, entreprises, décideurs publics et le grand public. L’histoire de l’art IA n’est pas terminée : nous vivons en ce moment l’un de ses chapitres les plus décisifs.
Une chose est sûre : ignorer l’IA ne la fera pas disparaître, pas plus que fermer les yeux sur les défis bien réels qu’elle pose. Avancer suppose de s’engager pleinement : reconnaître les problèmes avec lucidité, rester ouvert aux opportunités et défendre sans concession l’équité.
Quant à savoir si l’IA peut réellement être créative, la question est peut-être mal posée. La créativité n’est pas une qualité binaire, que l’on possède ou non. Elle se déploie sur des spectres, dans la collaboration, dans des combinaisons inattendues. Si les cinquante premières années de l’art IA nous ont appris une chose, c’est que la créativité est plus vaste et plus étrange que nous ne l’imaginions. Et que les humains, pour le meilleur comme pour le pire, semblent déterminés à la partager.
Le prochain chapitre s’écrit en ce moment. Contribuez avec discernement.