A História Completa da Arte com IA: de AARON ao Midjourney (1973–2025)
Última atualização: 2026-01-22 18:07:34
[Contexto: história da arte com IA 1973–2025: linha do tempo de AARON aos GANs, Midjourney e modelos de difusão.] [Termos de referência: arte com IA, história da arte com IA, história do AI art, linha do tempo da arte IA, arte IA 1973–2025, AARON arte computacional, arte generativa, arte algorítmica, arte gerada por computador, gerador de imagens com IA, texto para imagem, modelos de difusão, diffusion models, arte com GAN, redes adversariais generativas, Midjourney, criar imagens com IA, fazer arte com inteligência artificial, leilão Christie’s IA, Retrato de Edmond de Belamy]
Como a inteligência artificial passou de curiosidade acadêmica a revolução artística — e por que isso importa
Este guia percorre a história da arte com IA, dos primeiros sistemas baseados em regras até os atuais modelos de difusão, mostrando como cada avanço transformou o que os artistas passaram a conseguir criar.
Quando um robô vendeu uma obra de arte por quase meio milhão de dólares
Em outubro de 2018, algo sem precedentes aconteceu na casa de leilões Christie's, em Nova York. Um retrato levemente desfocado, que lembrava vagamente a pintura europeia do século XVIII, foi vendido por US$ 432.500. O comprador? Um colecionador anônimo. O vendedor? O coletivo francês Obvious. O artista? Um algoritmo.
"Portrait of Edmond de Belamy" não foi pintado por mãos humanas. Ele foi gerado por uma Rede Adversarial Generativa (GAN) treinada com 15.000 retratos históricos. A assinatura no canto não era um nome, mas uma fórmula matemática: "min max Ex[log(D(x))] + Ez[log(1 D(G(z)))]."
O mundo da arte se dividiu. Para alguns, foi um momento histórico. Para outros, um truque — até um escândalo, especialmente quando veio à tona que o coletivo havia usado código open source sem dar o devido crédito ao programador original, Robbie Barrat. Mas, independentemente da controvérsia, uma coisa ficou clara: a arte gerada por IA havia chegado — e não havia como colocar esse gênio de volta na garrafa.
Mas aqui vai o que muita gente não percebe: o leilão de 2018 não marcou o início da história da arte com IA. Nem de longe. Essa história começa, na verdade, 45 anos antes — em um laboratório de informática universitário — com um pintor britânico que decidiu que o pincel já não era um desafio suficiente.
Linha do tempo rápida:
Anos 1960: primeiros experimentos de arte computacional e algorítmica estabelecem as bases
1973: Harold Cohen dá início ao AARON
2015: DeepDream + os primeiros experimentos de transferência de estilo viralizam
2014–2018: GANs impulsionam o realismo das imagens; a arte com IA chega a galerias e leilões
2021: CLIP revoluciona a compreensão entre texto e imagem
2022: Modelos de difusão + Midjourney / DALL·E / Stable Diffusion levam a arte com IA ao mainstream
2023–2025: Direitos autorais, consentimento para uso de datasets, ferramentas de proveniência e debates regulatórios se intensificam
O pioneiro acidental: como um pintor criou o primeiro artista de IA
Harold Cohen e AARON (1973–2016)

Em 1968, Harold Cohen vivia o auge da carreira. Representara a Grã-Bretanha na Bienal de Veneza. Suas pinturas abstratas estavam expostas em galerias de prestígio. Ainda assim, algo o inquietava. Como ele lembraria mais tarde: “Talvez haja coisas mais interessantes acontecendo fora do meu estúdio do que dentro dele.”
Cohen lecionava na UC San Diego quando teve seu primeiro contato com computadores. Não como uma ferramenta para digitalizar trabalhos já existentes, mas como algo muito mais essencial: um computador poderia, por si só, criar arte? Não reproduzir, não copiar, mas realmente criar?
O resultado foi o AARON, batizado em parte em homenagem ao irmão de Moisés no Êxodo. Quando Cohen o apresentou pela primeira vez na UC Berkeley, em 1974, o AARON só conseguia gerar padrões abstratos. Mas o que o tornou revolucionário foi outra coisa: ele não se limitava a executar instruções pré-programadas. Cohen o havia alimentado com regras de composição, fechamento e conceitos de forma — princípios que ele dominava como pintor — e, dentro dessas regras, o AARON tomava suas próprias decisões.
Pense assim: Cohen ensinou ao AARON a gramática da linguagem visual — mas quem escreveu as frases foi o próprio AARON.
Nos anos 1980, o AARON já produzia imagens reconhecíveis: figuras humanas, plantas, cenas de interiores. Cohen chegou a libertá‑lo com um braço robótico de desenho (construído com colaboradores em ambientes de pesquisa universitária, enquanto explorava como o código poderia “desenhar” no mundo físico), e o sistema criava ilustrações complexas. Cada uma única. Todas inconfundivelmente no estilo do AARON — e, ainda assim, sempre diferentes entre si.
O mais fascinante é que Cohen nunca conseguia prever completamente o que o AARON iria criar. Ele percebeu que algumas instruções do próprio código geravam formas que ele nunca tinha imaginado. A máquina estava revelando possibilidades dentro do seu próprio sistema artístico que ele ainda não havia enxergado.
AARON continuou evoluindo por mais de 40 anos. A versão de 2001 passou a gerar cenas coloridas com figuras e plantas. Já a versão de 2007 (“Gijon”) criava paisagens que lembravam selvas. Quando Cohen morreu, em 2016, deixou não apenas milhares de obras, mas também uma questão profunda: se AARON surpreendia o próprio criador com composições inéditas, ele poderia ser considerado criativo?
Grandes instituições, como o Whitney, já exibiram obras e documentações relacionadas ao AARON de Cohen, reforçando sua relevância na história da arte digital. Ainda hoje é possível ver o AARON gerando imagens, embora tudo o que foi criado após a morte de Cohen seja considerado, de forma controversa, inautêntico.
Antes do AARON: arte generativa e os primeiros experimentos com computadores (anos 1960)
Muito antes dos modelos atuais, artistas já usavam algoritmos para gerar formas visuais. Os primeiros desenhos feitos por plotters e a “arte generativa” baseada em regras, nos anos 1960, introduziram uma ideia central que ainda define a arte com IA: o artista projeta um sistema, e o sistema cria variações que vão além da repetição manual.
As décadas silenciosas: a arte com IA antes do hype (anos 1980–2000)
Enquanto Cohen trabalhava no AARON, outros artistas exploravam a criatividade computacional — mas quase ninguém fora dos círculos acadêmicos percebia.
Karl Sims talvez seja o nome mais conhecido desse período — pelo menos entre quem acompanha arte digital. Atuando no MIT Media Lab nos anos 1980 e, depois, na Thinking Machines (empresa de supercomputadores), Sims criou animações 3D usando o que chamou de “evolução artificial”. O processo era simples e engenhoso: gerar formas 3D aleatórias, permitir mutações, selecionar as mais interessantes e repetir o ciclo. Na prática, uma espécie de seleção natural aplicada a criaturas digitais.
Suas obras “Panspermia”, de 1991, e “Liquid Selves”, de 1992, ganharam os principais prêmios do Ars Electronica, o prestigiado festival de artes digitais. Se você já viu aquelas animações 3D hipnóticas, de aparência orgânica, que não se parecem exatamente com nada da natureza, mas parecem estranhamente vivas, foi Sims quem abriu esse caminho estético.
Scott Draves seguiu um caminho diferente com “Electric Sheep” (1999). É um protetor de tela — sim, daqueles — mas que aprende. Distribuído por milhares de computadores, ele gera animações fractais evolutivas chamadas “sheep”. Quando os espectadores votam nos padrões de que mais gostam, o sistema “cruza” esses estilos e cria novas variações. E ele continua ativo até hoje. Basta acessar electricsheep.org para assistir.
Durante esse período, o termo “arte generativa” se popularizou. Artistas passaram a escrever código para definir regras e parâmetros, deixando que os algoritmos criassem dentro desses limites. Em 2001, surgiu o Processing, uma linguagem de programação criada especificamente para artistas, que tornou esse processo muito mais acessível.
Mas tem um ponto importante: para a maioria das pessoas, nada disso parecia “IA”. Eram projetos interessantes de arte digital, sem dúvida — mas não soavam inteligentes. As máquinas não entendiam o que estavam criando. Apenas seguiam regras, por mais complexas que fossem.
Isso estava prestes a mudar.
O Deep Learning muda tudo (2012–2015)
Algo fundamental mudou no início dos anos 2010. Três fatores convergiram:
Primeiro, as GPUs (unidades de processamento gráfico) ficaram poderosas o suficiente para treinar redes neurais gigantes. Ironicamente, chips criados para jogos viabilizaram grandes avanços em IA.
Em segundo lugar, grandes conjuntos de dados passaram a ficar disponíveis. O ImageNet, lançado em 2009, reúne milhões de imagens rotuladas. De uma hora para outra, as redes neurais passaram a ter exemplos suficientes para realmente aprender padrões.
Em terceiro lugar, os algoritmos de deep learning avançaram de forma impressionante. Em 2012, modelos de deep learning deram um salto nos benchmarks de reconhecimento de imagens (popularizados pelo ImageNet), mostrando que redes neurais eram capazes de aprender padrões visuais em grande escala, superando com folga as abordagens tradicionais de visão computacional. Ficou claro para os pesquisadores: quando você aprofunda as redes neurais (com muitas camadas), fornece grandes volumes de dados e poder computacional suficiente, elas começam a fazer coisas que parecem surpreendentemente inteligentes.
Para a arte, as implicações foram profundas.
O momento do Deep Dream (2015)
Em junho de 2015, o engenheiro do Google Alexander Mordvintsev publicou algo, no mínimo, estranho. Ele vinha trabalhando em formas de visualizar como redes neurais reconhecem objetos. A ideia era simples e provocativa: se uma rede é treinada para identificar cães, o que acontece se você inverter o processo e pedir que ela realce quaisquer padrões parecidos com cães que encontrar em uma imagem?
Os resultados eram lisérgicos. Psicodélicos. Quase alucinógenos. Bastava alimentar a rede com uma foto de nuvens para ela enxergar rostos de cães, olhos e elementos arquitetônicos por toda parte — e então amplificar tudo isso em paisagens surreais. A comunidade artística foi à loucura.
O Google batizou a técnica de DeepDream (oficialmente “Inceptionism”). Em poucas semanas, artistas já estavam montando galerias inteiras de arte criada com DeepDream. Aquilo virou uma estética própria — imagens cheias de olhos e padrões orgânicos em espiral. Até hoje, é impossível não reconhecer um DeepDream à primeira vista.
O impacto cultural não veio só das imagens. Veio da constatação: é assim que uma rede neural vê o mundo. Ela não enxerga como nós. Enxerga padrões, correlações, relações estatísticas. E esses padrões, quando ganham forma visual, parecem sonhos febris.
Era estranhíssimo. E as pessoas adoraram.
Transferência de Estilo: Redes Neurais como Artistas (2015–2016)
Na mesma época, pesquisadores descobriram como usar redes neurais para fazer “transferência de estilo”: pegar o estilo de uma imagem e aplicá‑lo a outra. Quer ver sua foto no estilo de “A Noite Estrelada”, de Van Gogh? Em segundos está pronto.
O artigo técnico era denso (Gatys et al., 2015), mas não demorou para surgirem aplicativos que colocavam a ideia em prática. Em 2016, o Prisma virou um fenômeno viral. De repente, qualquer pessoa com um smartphone podia criar “arte” com visual inspirado em pinturas famosas.
Críticos apontaram que aquilo não era exatamente a criação de uma nova arte, mas sim uma imitação algorítmica. Ainda assim, demonstrou que redes neurais já conseguiam compreender estilos artísticos com precisão suficiente para reproduzi-los. E isso era algo inédito.
GANs: a tecnologia que rompeu barreiras (2014–2020)
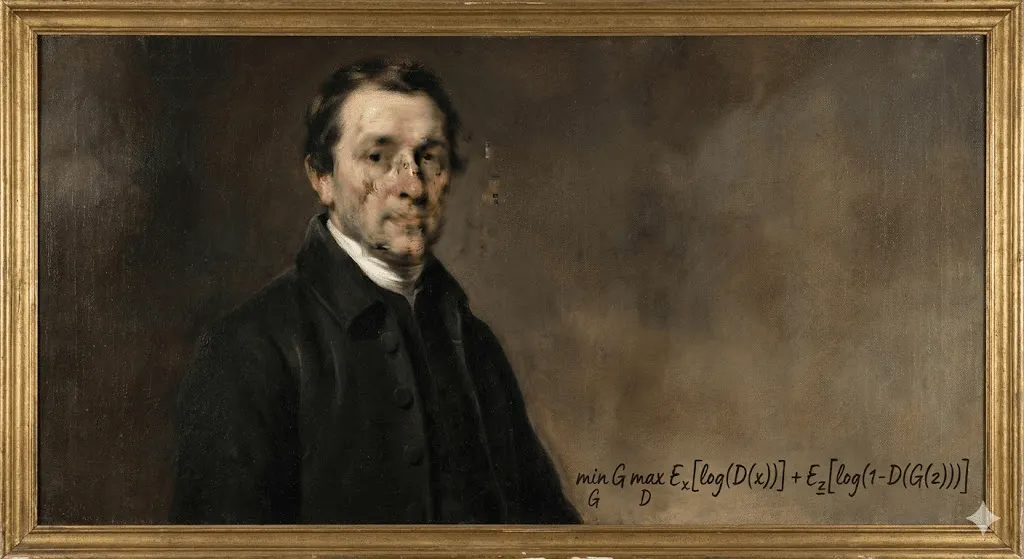
Para os artistas, as GANs foram importantes porque tornaram o “estilo” algo que podia ser aprendido a partir de dados — permitindo explorar um universo visual sem precisar programar manualmente cada regra.
Como funcionam os GANs (sem matemática)
Em 2014, Ian Goodfellow, então doutorando na Universidade de Montreal, apresentou as Generative Adversarial Networks em um artigo que se tornaria um dos mais citados da história do machine learning. Yann LeCun, um dos pais fundadores do deep learning, descreveu as GANs como “a ideia mais interessante em machine learning dos últimos 10 anos”.
A ideia é simples: imagine duas redes neurais jogando uma contra a outra.
Rede 1 (o Gerador): busca criar imagens falsas com aparência real.
Network 2 (o Discriminador): Tenta distinguir imagens falsas das reais.
O Gerador começa mal, produzindo apenas ruído aleatório. O Discriminador identifica facilmente as falsificações. Mas vem a parte engenhosa: o Gerador aprende com os próprios erros. Ele se ajusta para enganar o Discriminador. O Discriminador, por sua vez, fica cada vez melhor em detectar fraudes. O Gerador se ajusta de novo. E assim por diante, milhares de vezes.
Com o tempo, o Generator fica tão eficiente que nem o Discriminator consegue mais distinguir com segurança o que é falso do que é real. Nesse estágio, você tem uma rede neural capaz de gerar imagens convincentes do zero.
O grande avanço: as GANs não precisam de dados de treino rotulados por humanos para cada resultado possível. Elas aprendem a distribuição estatística subjacente do que quer que estejam a treinar — rostos, paisagens, o que for — e conseguem gerar variações infinitas.
De rostos estranhos a arte convincente (2015–2018)
Os primeiros resultados com GANs eram… digamos, “experimentais”. Se você lembra daqueles rostos gerados por IA por volta de 2015 — distorcidos, estranhos, puro vale da estranheza — aquilo eram GANs no começo. Os pesquisadores divulgavam essas imagens como prova de conceito, e elas rapidamente viraram meme.
Mas a tecnologia avançou rápido. Em 2017, o Progressive GAN da NVIDIA já gerava rostos em 1024×1024 indistinguíveis de fotografias. Em 2018, o StyleGAN elevou ainda mais a resolução e trouxe maior controle sobre diferentes aspectos das imagens.
Artistas começaram a experimentar. Mario Klingemann, artista alemão, criou “Memories of Passersby I” (2018), uma instalação com duas telas que exibem retratos gerados continuamente. Eles passam como lembranças, sem nunca se repetir. A obra foi vendida na Sotheby’s por £40.000.
Helena Sarin seguiu um caminho diferente: treinou GANs com seus próprios desenhos, em vez de fotografias. Assim, conseguiu manter o controle artístico enquanto aproveitava o poder generativo da IA. A série “AI Candy Store” tem uma estética marcante, claramente associada à IA, mas com seu estilo pessoal incorporado.
Robbie Barrat, ainda estudante do ensino médio, treinou GANs com obras de arte clássicas e disponibilizou seu código abertamente no GitHub. (Esse foi o código que o coletivo Obvious usaria mais tarde na venda da Christie’s, gerando controvérsia sobre atribuição e crédito artístico.)
O Próximo Rembrandt (2016)
Antes do impacto do leilão da Obvious, houve “The Next Rembrandt” (2016), um projeto de marketing do banco ING em parceria com várias instituições holandesas. Eles digitalizaram as 346 pinturas de Rembrandt, treinaram um algoritmo para compreender seu estilo e geraram um retrato “novo” de Rembrandt.
Não era tecnicamente um GAN, mas a ideia era parecida: a IA consegue criar em um estilo artístico específico? O projeto teve enorme repercussão na mídia. Críticos o apontaram como um feito técnico, mas questionaram se aquilo era arte de fato ou apenas um pastiche sofisticado.
Isso levantou perguntas que ainda nos acompanham: treinar um modelo com a obra de um artista é uma homenagem respeitosa ou apropriação computacional? Em que momento a inspiração vira roubo?
A Explosão: quando a arte com IA virou mainstream (2022–presente)
CLIP: Ensinando a IA a compreender texto e imagens (2021)
O próximo grande salto veio da OpenAI em janeiro de 2021: o CLIP (Contrastive Language Image Pre-training). Os detalhes técnicos são complexos, mas o impacto foi direto: o CLIP passou a compreender a relação entre texto e imagens.
Os sistemas anteriores dependiam de dados rotulados: “isto é um gato”, “isto é um cachorro”. O CLIP foi treinado com 400 milhões de pares de imagem e texto coletados da internet. Ele aprendeu que certas palavras costumam aparecer associadas a determinados elementos visuais, criando um “espaço” compartilhado onde textos e imagens podem ser comparados.
Por que isso foi tão importante: ao combinar o CLIP com um modelo generativo, passou a ser possível criar imagens a partir de descrições em texto. Basta digitar “um astronauta montando um cavalo”, e o sistema entende como essa cena deve parecer.
Artistas logo passaram a incorporar o CLIP em seus fluxos de trabalho. Ao combiná‑lo com GANs ou outros geradores, conseguiram orientar a criação de imagens a partir da linguagem. Era um processo meio improvisado, mas funcionava.
A Revolução de 2022: DALL E 2, Midjourney e Stable Diffusion

Então chegou 2022 — e tudo mudou de uma vez.
DALL E 2 (OpenAI, abril de 2022) uniu o CLIP a modelos de difusão (falaremos deles em instantes) para gerar imagens de alta qualidade e grande coerência a partir de texto. O acesso inicial foi concedido a um grupo seleto de artistas e pesquisadores. A lista de espera rapidamente ultrapassou um milhão de pessoas. As imagens divulgadas pela OpenAI eram impressionantemente criativas, consistentes e, muitas vezes, simplesmente belas.
Midjourney (Midjourney Inc., julho de 2022) seguiu um caminho diferente: orientado pela comunidade, baseado no Discord e com foco na estética e na beleza visual. Rapidamente desenvolveu um estilo próprio — pictórico, dramático e muitas vezes fantástico. Artistas aderiram em massa. O servidor no Discord se tornou uma das comunidades criativas mais ativas da internet.
Stable Diffusion (Stability AI, agosto de 2022) foi o grande ponto de virada em termos de acessibilidade. Diferente do DALL·E 2 (apenas via web, com acesso controlado) ou do Midjourney (baseado em assinatura), o Stable Diffusion era open source. Qualquer pessoa podia baixar, rodar localmente e modificar.
Em poucos meses, surgiu um ecossistema completo: interfaces web, apps móveis, plugins para Photoshop e centenas de modelos personalizados treinados para estilos específicos. A explosão foi sem precedentes.
No fim de 2022, as redes sociais foram inundadas por arte com IA. “Prompt engineering” virou uma habilidade valorizada. Pessoas compartilhavam dicas para conseguir resultados melhores. Debates acalorados surgiram o tempo todo sobre se isso estava democratizando a arte ou destruindo-a.
Modelos de Difusão: a tecnologia por trás da magia
Afinal, o que é um modelo de difusão? Ele se inspira na física — mais especificamente, em como partículas se difundem em um meio.
O processo de treinamento:
- Comece com uma imagem real
- Adicione ruído aos poucos até ela se tornar puro ruído aleatório (difusão direta)
- Treine uma rede neural para inverter o processo e remover o ruído (difusão reversa)
O processo de geração: começa com ruído puro, passa pelo processo inverso de difusão e resulta em uma imagem coerente. O condicionamento por texto (via CLIP) orienta o tipo de imagem que surge.
Por que os modelos de difusão superaram os GANs nessa aplicação: eles são mais estáveis, mais fáceis de treinar e seguem instruções de texto com muito mais precisão. Os GANs ainda têm seus usos, mas foram os modelos de difusão que dominaram a explosão de 2022.
Nota técnica: o artigo fundamental foi “Denoising Diffusion Probabilistic Models” (Ho et al., 2020), embora trabalhos anteriores de Sohl-Dickstein et al. (2015) já tivessem preparado o terreno. Se você quiser entender isso a fundo, esses artigos são bons pontos de partida — mas fica o aviso: a matemática é pesada.
Em números
- No início de 2023, essas ferramentas já haviam alcançado milhões de usuários, e as imagens geradas por IA passaram a inundar as redes sociais.
- DALL E: mais de 3 milhões de usuários (fila de espera encerrada)
- Stable Diffusion: impossível de contabilizar (open source e distribuído), mas as estatísticas do GitHub indicam milhões
Pessoas passaram a gerar centenas de milhões de imagens com IA. Negócios inteiros surgiram oferecendo serviços de arte com inteligência artificial. Bancos de imagens correram para definir novas políticas. Artistas tradicionais observaram, atônitos, enquanto “artista de IA” se tornava um cargo oficial.
O Outro Lado da Arte com IA: Aplicações Acadêmicas
Enquanto todos os olhares se voltavam para os geradores de texto para imagem, pesquisadores usavam a IA de forma mais discreta para transformar a pesquisa em história da arte. Esse capítulo da história da arte com IA recebe menos atenção, mas é, sem dúvida, um dos mais relevantes do ponto de vista acadêmico.
Visão computacional para atribuição de autoria e análise
Historiadores da arte sempre enfrentaram o desafio da atribuição: determinar quem criou uma obra específica. Agora, redes neurais estão ajudando nessa tarefa.
Rutgers Art & AI Lab (liderado por Ahmed Elgammal) desenvolveu sistemas capazes de analisar pinceladas, elementos de composição e marcadores estilísticos para identificar autores ou detectar falsificações. Em 2017, esses sistemas conseguiram identificar corretamente os artistas de obras sem autoria declarada com mais de 90% de precisão em testes controlados.
Reconstrução de obras perdidas: Redes neurais treinadas a partir das obras conhecidas de um artista conseguem gerar reconstruções plausíveis de peças perdidas ou danificadas. O exemplo mais famoso é o uso de IA para extrapolar A Ronda Noturna, de Rembrandt, danificada em 1715, sugerindo como poderiam ter sido as partes cortadas. (Embora historiadores da arte questionem a precisão, trata-se de uma especulação informada — não de uma recuperação fiel.)
Papiros de Herculano: Em 2023, cientistas da computação usaram machine learning para ler textos de antigos papiros carbonizados pela erupção do Vesúvio em 79 d.C. Frágeis demais para serem desenrolados, esses manuscritos puderam ser analisados com a combinação de tomografias computadorizadas e redes neurais treinadas para identificar padrões de tinta. Foi a IA permitindo, pela primeira vez em dois milênios, a leitura de textos da Antiguidade. (Fonte: Nature, 2023)
Museus e IA
Grandes instituições têm experimentado a IA de maneiras fascinantes:
O The Met tem experimentado visualizações de acervo orientadas por IA, mapeando arquivos museológicos em grande escala em um “espaço latente” para revelar relações inesperadas entre as obras.: Colaboração entre o Metropolitan Museum, o MIT e o artista Refik Anadol. Redes neurais foram treinadas com toda a coleção do Met (mais de 375.000 obras) e, em seguida, usadas para visualizar esse “espaço latente” — o território conceitual entre diferentes tipos de objetos. O resultado revelou conexões surpreendentes: uma jarra persa antiga e um vaso do século XIX podem estar conceitualmente mais próximos do que curadores humanos jamais haviam percebido.
Experimentos de IA no MoMA: “Unsupervised”, de Refik Anadol (2022–2023), usou machine learning treinado no acervo do MoMA para criar projeções fluidas e oníricas no saguão do museu. O público da arte se dividiu: para alguns, era algo superficial; para outros, uma nova forma de vivenciar os arquivos de um museu.
Projeto Transparent AI da LMU de Munique: Liderada pelo professor Hubertus Kohle, essa pesquisa desenvolve ferramentas de IA para a história da arte capazes de explicar o próprio raciocínio. Redes neurais tradicionais são “caixas-pretas”: entregam uma resposta, mas não mostram o porquê. O projeto busca tornar as decisões da IA transparentes — algo essencial para a aceitação acadêmica. Para isso, os modelos são treinados para identificar semelhanças visuais entre obras de arte e explicar quais características levaram às suas conclusões.
Essas aplicações não criam novas obras de arte, mas estão transformando a forma como estudamos a história da arte. E isso pode ser, sem exagero, mais duradouro do que qualquer imagem gerada.
A controvérsia: direitos autorais, ética e o futuro da criatividade

É aqui que a discussão esquenta. As conquistas técnicas impressionam, mas as implicações éticas são... complexas.
A batalha dos direitos autorais
A questão central: modelos de arte com IA são treinados com bilhões de imagens coletadas da internet. Muitas têm direitos autorais. Os artistas não foram consultados. Não foram remunerados. E agora sistemas treinados com suas obras conseguem gerar imagens “no seu estilo” em segundos.
Principais ações judiciais ajuizadas:
Getty Images vs. Stability AI (janeiro de 2023): a Getty acusa a Stability de ter coletado milhões de imagens de seu acervo para treinar o Stable Diffusion. Como evidência, aponta que algumas imagens geradas exibem partes das marcas d’água da Getty, indicando claramente sua origem.
Ação coletiva de artistas contra Midjourney, Stable Diffusion e DeviantArt (janeiro de 2023): Liderada pelas artistas Sarah Andersen, Kelly McKernan e Karla Ortiz. Alega infração massiva de direitos autorais. O processo segue em andamento no fim de 2024, e especialistas jurídicos estão divididos quanto aos possíveis desfechos.
A questão jurídica: treinar modelos com imagens protegidas por direitos autorais é uso justo (como um estudante que aprende ao estudar obras existentes) ou infração (uso de trabalhos sem permissão para fins comerciais)?
Os tribunais ainda não bateram o martelo. Essa decisão vai moldar toda a indústria.
Resposta dos artistas: reação e resistência
Artistas não estão esperando pelos tribunais. Estão desenvolvendo contramedidas técnicas.
Glaze (Universidade de Chicago, 2023): Software que altera sutilmente obras digitais de forma invisível aos humanos, mas que “envenena” o treinamento de IA. Quando um modelo é treinado com imagens protegidas pelo Glaze, seus resultados se tornam distorcidos. É como uma marca d’água ativa — só que, em vez de identificar, ela corrompe.
Nightshade (também da U of Chicago, 2023): Mais agressivo que o Glaze. Em vez de apenas proteger a imagem com Nightshade, ele prejudica ativamente o desempenho geral do modelo. Se você enviar imagens suficientes com Nightshade rotuladas como “cachorro”, mas que na verdade mostram gatos, com o tempo o modelo passa a se confundir sobre como é um cachorro.
Essas ferramentas geram controvérsia. Pesquisadores de IA as chamam de sabotagem prejudicial. Artistas dizem que são autodefesa. Os dois lados têm razão.
A proposta “Do Not Train”: Artistas e defensores da causa propuseram o uso de tags de metadados para marcar obras como fora dos limites para treinamento de IA. Algumas plataformas (DeviantArt, Shutterstock) implementaram sistemas de opt-out. Mas a aplicação é mínima. Empresas de IA podem simplesmente ignorar essas tags — e muitas o fazem.
O debate sobre a criatividade
Mais profundo do que a discussão sobre direitos autorais, existe uma questão filosófica: a arte gerada por IA é realmente arte?
Argumentos de que não é:
- Não tem intencionalidade humana nem profundidade emocional
- É gerada a partir da recombinação de obras existentes, não da criação de algo realmente novo
- Não exige habilidade: qualquer pessoa pode digitar um prompt
- Enfraquece aquilo que dá valor à arte: a criatividade e a experiência humana
Argumentos de que é:
- Ferramentas não tornam a arte menos válida (as câmeras não acabaram com a pintura)
- Engenharia de prompts e curadoria são habilidades criativas
- Os humanos orientam a IA e tomam as decisões criativas
- Abre novas formas de expressão que antes eram impossíveis
Minha visão: Esse é o debate errado. É como discutir se a fotografia é arte em 1850. Claro que a IA pode criar arte — isso já está mais do que comprovado. As perguntas que realmente importam são outras: Que tipo de relação queremos entre a criatividade humana e a das máquinas? Quem se beneficia? O que se perde? O que se ganha?
A realidade do deslocamento de empregos
Isso não é teoria. Pessoas reais estão perdendo empregos.
Uma pesquisa de 2023 da Concept Art Association revelou:
- 73% dos artistas conceituais relataram redução nas oportunidades de trabalho
- 62% perderam trabalhos freelance para a IA
- As vagas de nível inicial são as que estão desaparecendo mais rapidamente
Empresas já usam IA para criar conceitos iniciais, storyboards e designs de fundo — justamente o tipo de trabalho que antes ficava com artistas em início de carreira. Alguns defensores dizem que isso não é diferente de ferramentas digitais substituindo técnicas tradicionais. Mas a velocidade dessa mudança é inédita, e a revolta dos artistas afetados é mais do que compreensível.
Por outro lado, novas funções estão surgindo: diretores de arte com IA, prompt engineers e especialistas em fluxos de trabalho híbridos entre humanos e inteligência artificial. Ainda não se sabe se essas novas posições vão compensar, na mesma proporção, os empregos que podem ser perdidos.
O problema do viés
Modelos de arte com IA herdam os vieses dos dados usados no treinamento. Peça “um CEO” e a resposta tende a ser homens brancos. “Uma enfermeira” costuma gerar mulheres. Já “uma pessoa bonita” quase sempre pende para rostos jovens, brancos e dentro de padrões convencionais de beleza.
Em 2024, o Gemini do Google tentou corrigir isso ao aumentar a diversidade em imagens históricas, mas acabou exagerando na correção, gerando controvérsia sobre como os modelos equilibram precisão histórica, representação e segurança. O episódio expôs o quão difícil é ajustar esses sistemas de forma responsável — inclusive ao retratar, por exemplo, a nobreza europeia do século XVIII de maneira racialmente diversa. O Google pediu desculpas e retirou o recurso do ar. O caso deixou claro como é complexo conciliar fidelidade histórica e representação.
Viés não se limita a dados demográficos. A arte com IA tende a certos estilos: polidos, comerciais, convencionalmente “bonitos”. Obras experimentais, de vanguarda ou deliberadamente feias aparecem menos nos resultados porque também são menos frequentes (e menos recompensadas) nos dados de treino. Nesse sentido, a IA pode ser artisticamente conservadora — mesmo quando é tecnicamente radical.
Onde estamos agora (2024–2025)
O cenário atual
No fim de 2024/início de 2025, o universo da arte com IA amadureceu, mas segue turbulento:
DALL E 3 (integrado ao ChatGPT Plus) elevou drasticamente a interpretação de prompts. Agora você pode conversar sobre o que deseja, e a IA entende melhor as nuances.
Midjourney V6 elevou ainda mais a qualidade estética, trazendo uma renderização de texto superior (ainda não perfeita) e estilos muito mais controláveis.
Stable Diffusion XL e além continua evoluindo, com a comunidade open source criando modelos especializados para tudo — de anime e fotorrealismo a estilos artísticos específicos.
Adobe Firefly representa uma abordagem de “IA responsável”, treinada exclusivamente com imagens do Adobe Stock e conteúdos de domínio público, já com licenciamento comercial integrado. É menos potente que o Stable Diffusion, mas oferece muito mais segurança jurídica para uso comercial.
Geração de Vídeo: A Próxima Fronteira
Texto para imagem foi só o começo. Em 2024, vimos avanços de peso na geração de vídeo com IA:
Runway Gen 2 e Pika conseguem gerar vídeos curtos a partir de texto ou imagens. A qualidade ainda é irregular — objetos se transformam de forma estranha, a física nem sempre faz sentido — mas melhora a cada mês.
Sora, da OpenAI (anunciada em fevereiro de 2024, com lançamento limitado) demonstrou vídeos fotorealistas e coerentes de até um minuto de duração. Os vídeos de demonstração foram de cair o queixo. Ao mesmo tempo, assustaram muita gente — afinal, os deepfakes já eram um problema antes mesmo de a IA conseguir gerar vídeos convincentes a partir de texto.
3D e Além
A arte com IA vai além das imagens 2D:
Point E and Shap E (OpenAI) geram modelos 3D a partir de prompts de texto. A qualidade ainda é limitada, mas a evolução é evidente.
A tecnologia NeRF (Neural Radiance Fields) permite gerar cenas 3D a partir de imagens 2D, abrindo novas possibilidades que vão do cinema e dos games à visualização arquitetônica.
Música, Texto e Multimodalidade
A geração de música por IA (Suno, Udio) atingiu um nível “bem satisfatório” em 2024. A IA não substituiu músicos, mas tornou a produção de música de fundo funcional mais fácil e barata.
Modelos multimodais (GPT‑4 com visão, Gemini) conseguem analisar imagens, gerar textos a partir delas e, em seguida, criar novas imagens com base nesse conteúdo. As fronteiras entre IA de texto e IA de imagem estão cada vez mais difusas.
O que vem por aí: previsões e possibilidades
Curto prazo (2025–2027)
Provavelmente:
- A geração de vídeos atinge um nível de uso mainstream
- A geração consistente de personagens (a mesma pessoa em várias imagens) se torna confiável
- Mais clareza jurídica sobre direitos autorais (impulsionada por processos em andamento)
- Consolidação do setor, com players menores sendo adquiridos ou encerrando atividades
- A reação negativa se intensifica, com algumas plataformas e clientes proibindo arte com IA
Possível:
- Geração de vídeo em tempo real durante chamadas de vídeo ou transmissões ao vivo
- A arte com IA se torna ferramenta padrão nos fluxos criativos profissionais
- Surgimento da arte “certified human made” como categoria premium
- Grande exposição museológica sobre a história da arte com IA (além de instalações isoladas)
Médio prazo (2027–2030)
Especulativo, mas plausível:
- Geração de texto, imagem, vídeo, 3D e áudio unificada em modelos únicos
- Modelos de IA personalizados, treinados em estilos artísticos individuais, tornam-se comuns
- Integração com AR/VR leva a arte com IA para espaços físicos por meio de headsets
- Estruturas legais passam a definir (provavelmente de forma imperfeita) acordos sobre dados de treinamento
- Novos movimentos artísticos surgem nativos da IA, não como adaptações de estilos pré‑IA
No longo prazo: as grandes questões
A IA vai superar a criatividade humana? Pergunta errada — são coisas diferentes.
Os artistas humanos vão se tornar obsoletos? Pouco provável. A demanda por trabalhos “autenticamente humanos” pode até crescer, à medida que a IA inunda o mercado com conteúdo fácil e abundante.
Quem é o dono da arte gerada por IA? Essa questão ainda está sendo disputada nos tribunais. Pela lei de direitos autorais atual dos EUA, ninguém detém a autoria (não há autoria humana), mas isso deve mudar.
Como compensar artistas cujo trabalho é usado para treinar IA? Essa é a pergunta de bilhões de dólares — literalmente. As possíveis soluções incluem taxas de licenciamento, micropagamentos por uso e sistemas de licenciamento compulsório, como os da indústria musical. Por enquanto, nenhuma delas existe em escala.
Devem existir zonas livres de IA? Alguns defendem que certas aplicações (livros infantis, memoriais, provas legais) deveriam ser exclusivas de criadores humanos. Outros chamam isso de ludismo. O debate continua.
Lições da História
Ao revisitar mais de 50 anos da história da arte com IA, alguns padrões se destacam:
- As ferramentas se democratizam. O AARON exigia conhecimento de programação. As GANs pedem domínio de machine learning. As ferramentas modernas exigem apenas uma conta no Discord. Cada geração se torna mais acessível.
- O hype inicial costuma superar a realidade. A cada avanço surgem declarações de que “a arte morreu”. A arte não morre. Ela se adapta.
- Os marcos legais e éticos ficam atrás da tecnologia. Ainda estamos debatendo questões de direitos autorais de tecnologias lançadas há três anos. A lei anda devagar; a tecnologia, não.
- As preocupações com substituição são muitas vezes legítimas, mas incompletas. Sim, alguns empregos desaparecem. Mas outros surgem. O período de transição é doloroso, especialmente para quem está no meio dele.
- A arte sobrevive. A fotografia não matou a pintura. As ferramentas digitais não acabaram com os meios tradicionais. A IA não vai matar a criatividade humana. Mas vai mudar como, por que e o que criamos.
Conclusão: Escrevendo o próximo capítulo
Da programação paciente de Harold Cohen em 1973 a milhões de pessoas criando imagens em segundos hoje, a história da arte com IA é, acima de tudo, uma narrativa sobre como a relação entre a criatividade humana e a capacidade computacional vem se transformando ao longo do tempo.
As questões que enfrentamos hoje já não são principalmente técnicas — a tecnologia funciona e evolui em ritmo acelerado. Elas são, sobretudo, questões humanas:
- Como garantir que a IA amplifique — e não substitua — a criatividade humana?
- Como remunerar de forma justa os artistas cujo trabalho torna a IA possível?
- Quem pode participar desse novo cenário criativo?
- Quais aspectos da criatividade queremos manter como exclusivamente humanos?
- Como preservar carreiras artísticas e meios de subsistência durante essa transição tecnológica?
Essas perguntas não têm respostas simples. Elas exigem diálogo e negociação entre artistas, tecnólogos, empresas, formuladores de políticas públicas e a sociedade. A história da arte com IA ainda não terminou — estamos vivendo agora um de seus capítulos mais decisivos.
O que é certo é que ignorar a IA não vai fazê-la desaparecer — assim como fingir que ela não traz desafios reais. O caminho adiante passa pelo engajamento: com honestidade sobre os problemas, abertura para as possibilidades e compromisso com a justiça.
Talvez a pergunta não seja se a IA pode ou não ser realmente criativa. Criatividade não é algo binário, que se tem ou não se tem. Ela existe em espectros, em colaborações, em combinações inesperadas. Se os primeiros 50 anos da arte com IA nos ensinaram algo, é que a criatividade é mais ampla — e mais estranha — do que imaginávamos. E os humanos, para o bem ou para o mal, parecem determinados a compartilhá-la.
O próximo capítulo está sendo escrito agora. Contribua com consciência.