La storia completa dell’arte IA: da AARON a Midjourney (1973–2025)
Ultimo aggiornamento: 2026-01-22 18:07:34

Come l’intelligenza artificiale è passata da curiosità accademica a rivoluzione artistica — e perché tutto questo conta
Questa guida ripercorre la storia dell’arte generata dall’IA, dai primi sistemi basati su regole fino agli attuali modelli di diffusione, per mostrare come ogni svolta tecnologica abbia ampliato le possibilità creative degli artisti.
Quando un’opera creata da un algoritmo è stata venduta all’asta per quasi mezzo milione di dollari
Nell’ottobre 2018, alla casa d’aste Christie’s di New York accadde qualcosa di senza precedenti. Un ritratto leggermente sfocato, che richiamava vagamente la pittura europea del XVIII secolo, fu venduto per 432.500 dollari. L’acquirente? Un collezionista anonimo. Il venditore? Il collettivo francese Obvious. L’artista? Un algoritmo.
“Portrait of Edmond de Belamy” non è stato dipinto da mani umane. È stato generato da una rete generativa avversaria (GAN) addestrata su 15.000 ritratti storici. La firma nell’angolo non era un nome, ma una formula matematica: “min max Ex[log(D(x))] + Ez[log(1 D(G(z)))].”
Il mondo dell’arte si spaccò. Per alcuni fu un momento spartiacque. Per altri, una trovata pubblicitaria, se non addirittura uno scandalo — soprattutto quando emerse che il collettivo aveva utilizzato codice open source senza attribuirlo correttamente al programmatore originale, Robbie Barrat. Ma al di là delle polemiche, una cosa divenne evidente: l’arte generata dall’IA era arrivata, e non c’era più modo di rimettere il genio nella bottiglia.
Ma c’è un dettaglio che in pochi conoscono: quell’asta del 2018 non segna affatto l’inizio della storia dell’arte generata dall’IA. Nemmeno lontanamente. Tutto comincia in realtà 45 anni prima, in un laboratorio informatico universitario, quando un pittore britannico capisce che il pennello, da solo, non gli basta più.
Cronologia rapida:
Anni ’60: i primi esperimenti di arte al computer e algoritmica pongono le basi
1973: Harold Cohen dà vita a AARON
2015: DeepDream + le prime tecniche di style transfer diventano virali
2014–2018: GANs spingono il realismo delle immagini; l’arte IA entra in gallerie e aste
2021: CLIP sblocca la comprensione testo‑immagine
2022: modelli di diffusione + Midjourney / DALL·E / Stable Diffusion portano l’arte IA nel mainstream
2023–2025: si intensificano i dibattiti su copyright, consenso dei dataset, strumenti di provenienza e regolamentazione
Il pioniere per caso: come un pittore ha dato vita al primo artista IA
Harold Cohen e AARON (1973–2016)

Nel 1968 Harold Cohen era all’apice della sua carriera. Aveva rappresentato la Gran Bretagna alla Biennale di Venezia. I suoi dipinti astratti erano esposti in gallerie di grande prestigio. Eppure qualcosa continuava a tormentarlo. Come avrebbe ricordato più tardi: «Forse, fuori dal mio studio, stavano accadendo cose più interessanti di quelle che succedevano dentro».
Cohen insegnava alla UC San Diego quando entrò in contatto con i computer. Non come semplice strumento per digitalizzare il suo lavoro, ma come qualcosa di molto più radicale: un computer poteva davvero creare arte? Non riprodurre, non copiare, ma creare davvero?
Il risultato fu AARON, chiamato così anche in riferimento ad Aronne, il fratello di Mosè nell’Esodo. Quando Cohen lo presentò per la prima volta all’UC Berkeley nel 1974, AARON era in grado di generare solo pattern astratti. Ma l’aspetto davvero rivoluzionario era un altro: non si limitava a eseguire istruzioni predefinite. Cohen lo aveva programmato con regole su composizione, chiusura e forma — concetti che lui stesso padroneggiava come pittore — ma, all’interno di quei vincoli, AARON prendeva decisioni autonome.
Immaginalo così: Cohen ha insegnato ad AARON la grammatica del linguaggio visivo, ma AARON ha scritto le proprie frasi.
Negli anni ’80 AARON iniziò a produrre immagini riconoscibili: figure umane, piante, scene d’interno. Cohen lo lasciava “all’opera” con un braccio robotico per il disegno (realizzato insieme a collaboratori in contesti di ricerca universitaria, mentre sperimentava come il codice potesse “disegnare” nel mondo fisico), e il sistema generava disegni complessi. Ognuno unico. Tutti immediatamente riconducibili allo stile di AARON, ma mai uguali tra loro.
La cosa più affascinante è che Cohen non poteva mai prevedere fino in fondo cosa avrebbe creato AARON. Si rese conto che alcune istruzioni di programmazione generavano forme che non aveva mai immaginato. La macchina gli stava rivelando possibilità nascoste all’interno del suo stesso sistema artistico, prospettive che fino a quel momento non aveva visto.
AARON ha continuato a evolversi per oltre 40 anni. La versione del 2001 generava scene colorate con figure e piante. Quella del 2007 (“Gijon”) creava paesaggi simili a giungle. Alla morte di Cohen, nel 2016, non ha lasciato solo migliaia di opere, ma anche una domanda profonda: se AARON riusciva a sorprendere il suo stesso creatore con composizioni inedite, si poteva parlare di creatività?
Grandi istituzioni, tra cui il Whitney, hanno esposto opere e documentazione legate ad AARON di Cohen, confermandone il ruolo centrale nella storia dell’arte digitale. Ancora oggi è possibile vedere AARON generare immagini, anche se tutto ciò che è stato creato dopo la morte di Cohen è considerato, in modo controverso, non autentico.
Prima di AARON: arte generativa e i primi esperimenti al computer (anni ’60)
Molto prima dei modelli attuali, gli artisti sperimentavano già con algoritmi per generare forme visive. I primi disegni realizzati con plotter e l’arte generativa basata su regole degli anni ’60 hanno introdotto un’idea chiave che ancora oggi definisce l’arte IA: l’artista progetta un sistema, e il sistema produce variazioni che vanno oltre la ripetizione manuale.
I decenni silenziosi: l’arte IA prima dell’hype (anni ’80–2000)
Mentre Cohen lavorava su AARON, altri artisti sperimentavano forme di creatività computazionale, anche se al di fuori degli ambienti accademici quasi nessuno se ne accorgeva.
Karl Sims è probabilmente il nome più riconoscibile di questo periodo, almeno nell’ambito dell’arte digitale. Attivo negli anni ’80 al MIT Media Lab e poi in Thinking Machines (un’azienda di supercomputer), Sims realizzava animazioni 3D basate sull’“evoluzione artificiale”. Il suo metodo era semplice e radicale: generare forme 3D casuali, farle mutare, selezionare quelle più interessanti e ripetere il processo. In pratica, una selezione naturale applicata a creature digitali.
Con opere come “Panspermia” (1991) e “Liquid Selves” (1992) ha conquistato i premi più importanti di Ars Electronica, il prestigioso festival di arte digitale. Se hai mai visto quelle animazioni 3D ipnotiche, dall’aspetto organico, che non assomigliano davvero a nulla di naturale ma sembrano stranamente vive, quell’estetica l’ha aperta la strada proprio Sims.
Scott Draves ha seguito una strada diversa con "Electric Sheep" (1999). Sì, è uno screensaver — ve li ricordate? — ma uno che impara. Distribuito su migliaia di computer, genera animazioni frattali in continua evoluzione chiamate “sheep”. Quando gli spettatori votano i pattern che preferiscono, il sistema ne “alleva” di nuovi a partire da quelli più apprezzati. Ed è ancora attivo oggi. Basta andare su electricsheep.org per guardarlo in azione.
In questo periodo si afferma il termine “arte generativa”. Gli artisti scrivevano codice per definire regole e parametri, lasciando poi che fossero gli algoritmi a creare all’interno di questi vincoli. Nel 2001 nasce Processing, un linguaggio di programmazione pensato appositamente per gli artisti, che rende questo approccio molto più accessibile.
Ma c’è un punto chiave: per la maggior parte delle persone, tutto questo non sembrava davvero “IA”. Erano progetti di arte digitale affascinanti, certo, ma non apparivano intelligenti. Non capivano ciò che stavano creando. Si limitavano a seguire regole, per quanto complesse.
Ma stava per cambiare tutto.
Il deep learning cambia tutto (2012–2015)
All’inizio degli anni 2010 è avvenuto un cambiamento fondamentale. Tre elementi sono entrati in convergenza:
Per prima cosa, le GPU (graphics processing units) sono diventate abbastanza potenti da addestrare reti neurali di dimensioni enormi. Ironia della sorte, chip progettati per il gaming hanno reso possibili le grandi svolte dell’IA.
In secondo luogo, sono diventati disponibili dataset di grandi dimensioni. ImageNet, lanciato nel 2009, raccoglie milioni di immagini etichettate. All’improvviso, le reti neurali hanno avuto abbastanza esempi per imparare davvero i pattern.
Terzo, gli algoritmi di deep learning hanno fatto un salto enorme. Nel 2012, i modelli di deep learning hanno rivoluzionato i benchmark di riconoscimento delle immagini (resi popolari da ImageNet), dimostrando che le reti neurali potevano apprendere pattern visivi su larga scala e surclassando gli approcci tradizionali della computer vision. A quel punto i ricercatori hanno capito una cosa chiave: rendendo le reti neurali sufficientemente profonde (con molti livelli), fornendo abbastanza dati e potenza di calcolo, queste iniziano a produrre risultati sorprendentemente “intelligenti”.
Per il mondo dell’arte, le implicazioni furono profonde.
Il momento Deep Dream (2015)
Nel giugno 2015 l’ingegnere di Google Alexander Mordvintsev pubblicò qualcosa di decisamente insolito. Stava lavorando a un modo per visualizzare come le reti neurali riconoscono gli oggetti. L’intuizione era semplice e geniale: se una rete è addestrata a riconoscere i cani, cosa succede se si ribalta il processo e le si chiede di amplificare tutti i pattern “canini” che individua in un’immagine?
I risultati erano fuori di testa. Psichedelici. Perfino allucinatori. Bastava dargli in pasto una foto di nuvole perché la rete iniziasse a vedere ovunque musi di cani, occhi ed elementi architettonici, amplificandoli fino a trasformarli in paesaggi surreali. La comunità artistica impazzì.
Google lo chiamò DeepDream (ufficialmente “Inceptionism”). Nel giro di poche settimane, gli artisti iniziarono a creare vere e proprie gallerie di arte DeepDream. Nacque un’estetica autonoma: immagini riconoscibili per occhi ovunque e motivi organici vorticosi. Ancora oggi, un’immagine DeepDream si riconosce all’istante.
Ciò che lo rese culturalmente significativo non furono solo le immagini. Fu la presa di coscienza: è così che una rete neurale vede il mondo. Non vede ciò che vediamo noi. Vede pattern, correlazioni, relazioni statistiche. E quei pattern, una volta visualizzati, assomigliano a sogni febbrili.
Era straniante, quasi assurdo. E la gente lo adorava.
Style Transfer: le reti neurali diventano artiste (2015–2016)
Più o meno nello stesso periodo, i ricercatori capirono come usare le reti neurali per il “style transfer”: prendere lo stile di un’immagine e applicarlo a un’altra. Vuoi vedere una tua foto reinterpretata nello stile della “Notte stellata” di Van Gogh? Fatto in pochi secondi.
L’articolo tecnico era complesso (Gatys et al., 2015), ma le app che ne applicavano i principi si moltiplicarono rapidamente. Nel 2016 Prisma diventò virale. All’improvviso, chiunque con uno smartphone poteva creare “arte” che richiamava lo stile dei grandi maestri.
I critici sottolinearono che non si trattava davvero di creare nuova arte, ma di una mimica algoritmica. Tuttavia dimostrò che le reti neurali erano in grado di comprendere lo stile artistico abbastanza a fondo da replicarlo. E questa era una novità.
GAN: la tecnologia che ha segnato la svolta (2014–2020)
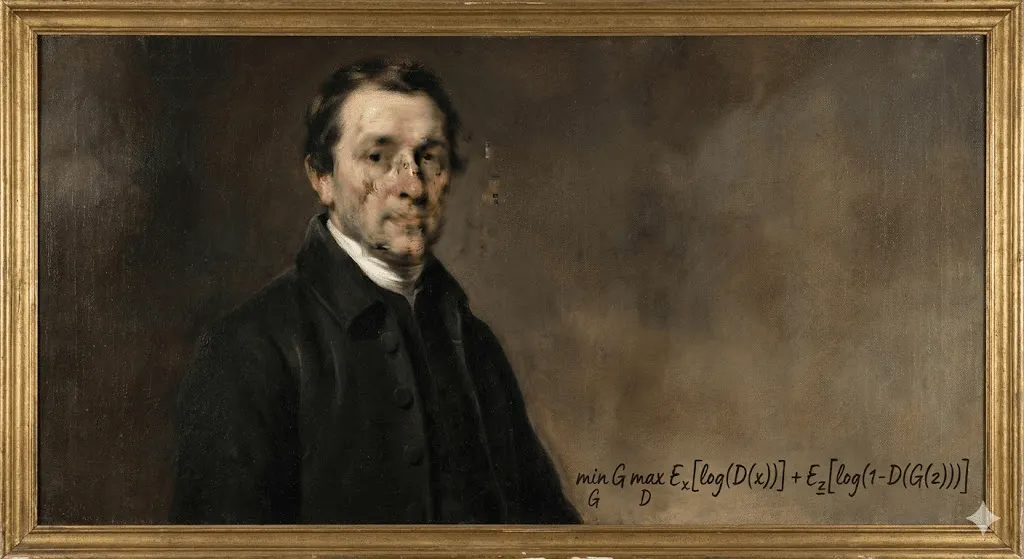
Per gli artisti, i GAN sono stati fondamentali perché hanno reso lo “stile” apprendibile dai dati, permettendoti di esplorare un intero universo visivo senza dover programmare a mano ogni singola regola.
Come funzionano le GAN (senza formule)
Nel 2014 Ian Goodfellow, allora dottorando all’Università di Montréal, presentò le Generative Adversarial Networks in un paper destinato a diventare uno dei più citati nel machine learning. Yann LeCun, padre fondatore del deep learning, definì le GAN «l’idea più interessante nel machine learning degli ultimi dieci anni».
Ecco l’idea di base: immagina due reti neurali che giocano una contro l’altra.
Rete 1 (il Generatore): Cerca di generare immagini false che sembrino reali.
Network 2 (the Discriminator): Cerca di distinguere le immagini false da quelle reali.
Il Generator parte malissimo, producendo solo rumore casuale. Il Discriminator smaschera subito i falsi. Ma ecco il punto chiave: il Generator impara dai propri errori. Si adatta per ingannare il Discriminator. Il Discriminator, a sua volta, diventa sempre più bravo a riconoscere i falsi. Il Generator si aggiusta di nuovo. E così via, avanti e indietro, migliaia di volte.
Col tempo, il Generatore diventa così efficace che nemmeno il Discriminatore riesce più a distinguere in modo affidabile il falso dal reale. A quel punto, hai una rete neurale capace di generare immagini credibili da zero.
La svolta: le GAN non hanno bisogno di dati di training etichettati dall’uomo per ogni possibile risultato. Imparano la distribuzione statistica di ciò su cui vengono addestrate — volti, paesaggi, qualsiasi cosa — e possono generare infinite variazioni.
Da volti bizzarri a opere davvero convincenti (2015–2018)
I primi risultati delle GAN erano… diciamo “sperimentali”. Se ti ricordi quei volti generati dall’IA intorno al 2015 — distorti, inquietanti, veri incubi da uncanny valley — ecco, erano le prime GAN. I ricercatori li condividevano come proof of concept, e nel giro di poco sono diventati meme.
Ma la tecnologia ha fatto passi da gigante in tempi rapidissimi. Già nel 2017, la Progressive GAN di NVIDIA era in grado di generare volti a 1024×1024 pixel indistinguibili da fotografie reali. Nel 2018, StyleGAN ha spinto ancora oltre la risoluzione, introducendo anche un controllo più fine sui diversi aspetti delle immagini.
Gli artisti iniziarono a sperimentare. Mario Klingemann, artista tedesco, realizzò "Memories of Passersby I" (2018), un’installazione con due schermi che mostrano ritratti generati all’infinito. Scorrono come ricordi, senza mai ripetersi. L’opera è stata venduta da Sotheby’s per £40.000.
Helena Sarin ha scelto una strada diversa: addestrare le GAN sui propri disegni invece che su fotografie. In questo modo ha mantenuto il controllo artistico, sfruttando al tempo stesso la potenza generativa dell’IA. La serie “AI Candy Store” ha un’estetica inconfondibile, chiaramente riconducibile all’AI, ma profondamente segnata dal suo stile personale.
Robbie Barrat, allora studente delle superiori, addestrò delle GAN su opere d’arte classica e condivise apertamente il suo codice su GitHub. (È lo stesso codice che Obvious avrebbe poi utilizzato per la vendita da Christie's, scatenando polemiche sull’attribuzione e sul riconoscimento della paternità artistica.)
The Next Rembrandt (2016)
Prima del clamore dell’asta di Obvious, c’è stato “The Next Rembrandt” (2016), un progetto di marketing promosso dalla banca ING insieme a diverse istituzioni olandesi. Sono stati digitalizzati 346 dipinti di Rembrandt, un algoritmo è stato addestrato a comprenderne lo stile e da lì è nato un “nuovo” ritratto firmato Rembrandt.
Non era tecnicamente una GAN, ma l’idea di fondo era simile: l’IA può creare opere nello stile di un artista specifico? Il progetto ebbe un’enorme risonanza mediatica. I critici lo definirono un traguardo tecnico, ma si divisero sul punto cruciale: era davvero arte o solo un pastiche sofisticato?
Ha sollevato domande con cui facciamo ancora i conti: addestrarsi sulle opere di un artista è un omaggio rispettoso o un’appropriazione computazionale? Quando l’ispirazione diventa furto?
L’esplosione: quando l’arte IA è diventata mainstream (2022–oggi)
CLIP: insegnare all’IA a comprendere testo e immagini (2021)
La svolta successiva arrivò da OpenAI nel gennaio 2021 con CLIP (Contrastive Language Image Pre‑training). I dettagli tecnici sono complessi, ma l’impatto fu immediato: CLIP era in grado di comprendere la relazione tra testo e immagini.
I sistemi precedenti richiedevano dati etichettati: «questo è un gatto», «questo è un cane». CLIP ha invece imparato da 400 milioni di coppie immagine-testo raccolte dal web, cogliendo come certe parole ricorrano insieme a specifiche caratteristiche visive. In questo modo ha creato uno “spazio” condiviso in cui testi e immagini possono essere messi a confronto.
Perché è stato un punto di svolta: combinando CLIP con un modello generativo, diventa possibile creare immagini a partire da una descrizione testuale. Scrivi “un astronauta a cavallo” e il sistema capisce immediatamente che aspetto dovrebbe avere.
Gli artisti hanno integrato rapidamente CLIP nei loro workflow. Abbinandolo a GAN o ad altri generatori, potevano guidare la creazione delle immagini tramite il linguaggio. Era macchinoso, ma funzionava.
La rivoluzione del 2022: DALL E 2, Midjourney, Stable Diffusion

Poi arrivò il 2022, e tutto cambiò di colpo.
DALL·E 2 (OpenAI, aprile 2022) ha unito CLIP e modelli di diffusione (ne parliamo tra poco) per generare immagini di alta qualità e sorprendentemente coerenti a partire dal testo. L’accesso iniziale è stato riservato a un gruppo selezionato di artisti e ricercatori. In breve tempo, la lista d’attesa ha superato il milione di persone. Le immagini condivise da OpenAI erano incredibilmente creative, coerenti e spesso di grande bellezza.
Midjourney (Midjourney Inc., luglio 2022) ha seguito una strada diversa: community‑driven, basato su Discord, con un focus dichiarato sulla bellezza estetica. In poco tempo ha sviluppato uno stile riconoscibile: pittorico, drammatico, spesso fantastico. Gli artisti vi sono accorsi in massa. Il server Discord è diventato una delle community creative più attive del web.
Stable Diffusion (Stability AI, agosto 2022) ha rappresentato una svolta decisiva in termini di accessibilità. A differenza di DALL·E 2 (solo web, accesso controllato) o Midjourney (basato su abbonamento), Stable Diffusion era open source. Chiunque poteva scaricarlo, usarlo in locale e modificarlo.
Nel giro di pochi mesi è nato un intero ecosistema: interfacce web, app mobile, plugin per Photoshop, centinaia di modelli personalizzati addestrati su stili specifici. Un’esplosione senza precedenti.
Alla fine del 2022, i social media sono stati invasi dall’arte generata dall’IA. Il “prompt engineering” è diventato una competenza a sé stante. Le persone si scambiavano consigli per ottenere risultati migliori. E ovunque scoppiavano discussioni: c’era chi parlava di una democratizzazione dell’arte e chi, invece, di una minaccia alla sua stessa esistenza.
Diffusion Models: la tecnologia dietro la magia
Che cos’è un modello di diffusione? L’idea arriva direttamente dalla fisica: descrive il modo in cui le particelle si diffondono all’interno di un mezzo.
Il processo di addestramento:
- Partire da un’immagine reale
- Aggiungere gradualmente rumore fino a trasformarla in puro caos casuale (diffusione in avanti)
- Addestrare una rete neurale a invertire il processo, rimuovendo il rumore (diffusione inversa)
Il processo di generazione: si parte da puro rumore, si applica il processo di diffusione inversa e si arriva a un’immagine coerente. Il condizionamento testuale (tramite CLIP) guida il tipo di immagine che prende forma.
Perché i modelli di diffusione hanno superato le GAN in questo ambito: sono più stabili, più facili da addestrare e seguono meglio i prompt testuali. Le GAN restano utili in alcuni casi, ma l’esplosione del 2022 è stata dominata dai modelli di diffusione.
Nota tecnica: l’articolo chiave è “Denoising Diffusion Probabilistic Models” (Ho et al., 2020), anche se lavori precedenti di Sohl-Dickstein et al. (2015) avevano già posto le basi. Se vuoi capire davvero come funzionano questi modelli, questi paper sono ottimi punti di partenza — ma avviso: la matematica è piuttosto impegnativa.
I numeri
- All’inizio del 2023, questi strumenti avevano già raggiunto milioni di utenti e le immagini generate dall’IA hanno iniziato a invadere le piattaforme social.
- DALL·E: oltre 3 milioni di utenti (lista d’attesa eliminata)
- Stable Diffusion: impossibile da quantificare (open source e distribuito), ma le statistiche di GitHub indicano milioni di utenti
Le persone hanno generato centinaia di milioni di immagini con l’IA. Sono nate intere aziende che offrivano servizi di arte con l’IA. I siti di stock fotografici si sono affannati a capire quali politiche adottare. Gli artisti tradizionali guardavano con sgomento mentre "AI artist" diventava un titolo professionale.
L’altra arte IA: applicazioni accademiche
Mentre l’attenzione di tutti era rivolta ai generatori text-to-image, i ricercatori utilizzavano l’IA in modo più silenzioso per rivoluzionare gli studi di storia dell’arte. È una parte della storia dell’AI art di cui si parla poco, ma che dal punto di vista accademico è forse ancora più rilevante.
Computer Vision per l’attribuzione e l’analisi
L’attribuzione — stabilire chi ha creato una determinata opera — è da sempre una sfida per gli storici dell’arte. Oggi le reti neurali stanno dando una mano.
Rutgers Art & AI Lab (guidato da Ahmed Elgammal) ha sviluppato sistemi in grado di analizzare pennellate, composizione e indicatori stilistici per attribuire le opere agli artisti o individuare eventuali falsi. Nel 2017, in test controllati, questi modelli sono riusciti a identificare correttamente gli autori di opere senza attribuzione con un’accuratezza superiore al 90%.
Ricostruzione di opere perdute: le reti neurali addestrate sulle opere note di un artista possono generare ricostruzioni plausibili di lavori andati persi o danneggiati. L’esempio più celebre: l’uso dell’IA per estrapolare “The Night Watch” di Rembrandt, danneggiato nel 1715, mostrando come avrebbero potuto apparire le parti tagliate. (Gli storici dell’arte ne discutono l’accuratezza: si tratta di una speculazione informata, non di un recupero.)
Herculaneum Scrolls: Nel 2023, un team di informatici ha utilizzato il machine learning per leggere testi contenuti in antichi rotoli carbonizzati dall’eruzione del Vesuvio nel 79 d.C. I papiri sono troppo fragili per essere srotolati, ma grazie a scansioni TAC e reti neurali addestrate è stato possibile individuare le tracce dell’inchiostro. È un esempio concreto di come l’IA ci stia permettendo di leggere testi antichi per la prima volta dopo 2.000 anni. (Fonte: Nature, 2023)
Musei e IA
Grandi istituzioni hanno sperimentato l’IA in modi davvero affascinanti:
Il Met ha sperimentato visualizzazioni basate sull’IA per mappare su larga scala i propri archivi museali in uno “spazio latente”, facendo emergere relazioni inaspettate tra le opere.: una collaborazione tra il Metropolitan Museum, il MIT e l’artista Refik Anadol. Hanno addestrato reti neurali sull’intera collezione del Met (oltre 375.000 opere), per poi visualizzare lo “spazio latente”: il territorio concettuale che collega tipologie diverse di oggetti. Il risultato ha messo in luce connessioni sorprendenti, ad esempio tra un ewer persiano antico e un vaso del XIX secolo, affinità che i curatori umani non avevano mai individuato.
Gli esperimenti di IA del MoMA: “Unsupervised” di Refik Anadol (2022–2023) ha utilizzato il machine learning, addestrato sulla collezione del MoMA, per creare proiezioni fluide e oniriche nella hall del museo. I puristi dell’arte si sono divisi: per alcuni era un esercizio spettacolare fine a sé stesso, per altri un nuovo modo di vivere e interpretare gli archivi museali.
Il progetto Transparent AI della LMU di Monaco: Guidata dal professor Hubertus Kohle, questa ricerca sviluppa strumenti di IA per la storia dell’arte capaci di spiegare il proprio ragionamento. Le reti neurali tradizionali sono delle “scatole nere”: forniscono una risposta, ma non il perché. Questo progetto rende le decisioni dell’IA trasparenti, un passaggio fondamentale per l’accettazione in ambito accademico. I modelli vengono addestrati a riconoscere le somiglianze visive tra le opere e a chiarire quali caratteristiche hanno portato alle loro conclusioni.
Queste applicazioni non creano nuove opere, ma stanno cambiando il modo in cui studiamo la storia dell’arte. Un impatto che, probabilmente, durerà più di qualsiasi immagine generata.
La controversia: copyright, etica e il futuro della creatività

È qui che il dibattito si accende davvero. I risultati tecnici sono impressionanti, ma le implicazioni etiche sono… complesse.
La battaglia sul copyright
Il nodo centrale è questo: i modelli di arte generata dall’IA vengono addestrati su miliardi di immagini raccolte online. Molte sono protette da copyright. Gli artisti non hanno dato il consenso. Non sono stati compensati. E oggi sistemi addestrati sulle loro opere possono creare immagini “nel loro stile” in pochi secondi.
Principali cause legali avviate:
Getty Images vs. Stability AI (gennaio 2023): Getty accusa Stability di aver raccolto milioni di immagini dal proprio archivio per addestrare Stable Diffusion. A sostegno della causa, presenta esempi di immagini generate che mostrano porzioni dei watermark di Getty, rendendo evidente la provenienza dei contenuti.
Class action degli artisti contro Midjourney, Stable Diffusion e DeviantArt (gennaio 2023): promossa dalle artiste Sarah Andersen, Kelly McKernan e Karla Ortiz. Accusa le piattaforme di violazioni massicce del diritto d’autore. Il procedimento è ancora in corso a fine 2024 e gli esperti legali restano divisi sui possibili esiti.
La questione legale è centrale: addestrarsi su immagini protette da copyright rientra nel fair use (come uno studente che impara studiando opere esistenti) oppure è una violazione, perché utilizza lavori altrui senza autorizzazione a fini commerciali?
I tribunali non si sono ancora espressi. La risposta plasmerà l’intero settore.
Le reazioni degli artisti: il contrattacco
Gli artisti non stanno aspettando i tribunali. Stanno sviluppando contromisure tecniche.
Glaze (University of Chicago, 2023): Software che modifica in modo impercettibile le opere digitali: all’occhio umano non cambia nulla, ma l’addestramento dell’IA viene “avvelenato”. Se un modello si allena su immagini Glazed, i risultati risultano distorti. È come un watermark attivo che, invece di identificare, compromette.
Nightshade (anche Univ. of Chicago, 2023): più aggressivo di Glaze. Non si limita a proteggere l’immagine “Nightshaded”, ma compromette attivamente le prestazioni complessive del modello. Se carichi abbastanza immagini Nightshaded etichettate come “cane” che in realtà mostrano gatti, col tempo il modello finisce per confondersi su cosa sia davvero un cane.
Questi strumenti sono controversi. Per i ricercatori di IA sono un sabotaggio dannoso. Per gli artisti, una forma di autodifesa. Entrambe le posizioni hanno senso.
La proposta “Do Not Train”: artisti e sostenitori hanno proposto l’uso di tag di metadati per segnalare le opere come non utilizzabili per l’addestramento dell’IA. Alcune piattaforme (DeviantArt, Shutterstock) hanno introdotto sistemi di opt-out. Ma l’applicazione è minima: le aziende di IA possono semplicemente ignorare questi tag, e molte lo fanno.
Il dibattito sulla creatività
Più ancora del copyright, c’è una questione filosofica di fondo: l’arte generata dall’IA può essere davvero considerata arte?
Cosa non è:
- È priva di intenzionalità umana e di una reale profondità emotiva
- Nasce dalla rielaborazione di opere esistenti, senza creare qualcosa di davvero nuovo
- Non richiede competenze: chiunque può scrivere un prompt
- Rischia di svuotare ciò che dà valore all’arte: la creatività e il percorso umano dietro l’opera
Argomentazioni:
- Gli strumenti non rendono l’arte meno valida (le fotocamere non hanno messo fine alla pittura)
- Il prompt engineering e la curatela sono competenze a tutti gli effetti
- Gli esseri umani guidano l’IA, prendendo decisioni creative
- Rende possibili nuove forme di espressione prima impensabili
Il mio punto di vista: è il dibattito sbagliato. È come chiedersi nel 1850 se la fotografia sia arte. Che l’IA possa creare opere d’arte lo abbiamo già visto. Le vere domande sono altre: che tipo di relazione vogliamo tra la creatività umana e quella delle macchine? Chi ne trae beneficio? Cosa si perde? Cosa si guadagna?
La realtà della perdita di posti di lavoro
Non è teoria: persone reali stanno perdendo il lavoro.
Un sondaggio del 2023 condotto dalla Concept Art Association ha rilevato:
- Il 73% dei concept artist ha segnalato una riduzione delle opportunità di lavoro
- Il 62% ha perso incarichi freelance a favore dell’IA
- Le posizioni entry-level sono quelle che stanno scomparendo più rapidamente
Le aziende stanno usando l’IA per il lavoro preliminare di concept, gli storyboard e i design di sfondo: esattamente quelle attività che un tempo erano affidate agli artisti agli inizi. C’è chi sostiene che non sia diverso da quando gli strumenti digitali hanno sostituito le tecniche tradizionali. Ma la velocità del cambiamento è senza precedenti, e la rabbia degli artisti coinvolti è più che comprensibile.
Dall’altra parte stanno emergendo nuove figure professionali: AI art director, prompt engineer, specialisti dei workflow ibridi uomo–IA. Resta da capire se questi ruoli riusciranno davvero a compensare, uno a uno, i posti di lavoro che si stanno perdendo.
Il problema dei bias
I modelli di AI art ereditano i bias dai dati su cui vengono addestrati. Chiedi “un CEO” e ottieni uomini bianchi. “Un infermiere” restituisce donne. “Una persona bella” è fortemente sbilanciata verso volti giovani, bianchi e conformi ai canoni estetici tradizionali.
Nel 2024 Google ha cercato di correggere il problema con Gemini aumentando la diversità nelle immagini storiche, ma ha finito per esagerare, scatenando polemiche su come i modelli possano bilanciare accuratezza storica, rappresentazione e sicurezza. Il caso ha messo in luce quanto sia difficile calibrare questi sistemi in modo responsabile, arrivando persino a raffigurare una nobiltà europea del Settecento irrealisticamente eterogenea dal punto di vista razziale. Google si è scusata e ha ritirato la funzione. L’episodio ha mostrato ancora una volta quanto sia complesso trovare un equilibrio tra fedeltà storica e rappresentazione.
I bias non riguardano solo le demografie. Nell’arte generata dall’IA emergono spesso estetiche levigate, commerciali, “belle” in modo convenzionale. Le forme più sperimentali, d’avanguardia o volutamente sgraziate compaiono di rado, perché sono meno presenti (e meno premiate) nei dati di addestramento. In questo senso, l’IA può essere artisticamente conservatrice anche quando è tecnicamente rivoluzionaria.
Dove siamo oggi (2024–2025)
Lo scenario attuale
Tra la fine del 2024 e l’inizio del 2025, il panorama dell’AI art è diventato più maturo, ma resta attraversato da forti tensioni e cambiamenti.
DALL·E 3 (integrato con ChatGPT Plus) ha migliorato in modo significativo l’interpretazione dei prompt. Ora puoi dialogare con l’IA su ciò che desideri ottenere, e il sistema comprende molto meglio sfumature, contesto e intenzioni.
Midjourney V6 ha portato la qualità estetica a un nuovo livello, con una resa del testo migliorata (anche se non ancora impeccabile) e stili molto più controllabili.
Stable Diffusion XL e oltre continuano a evolversi, con la community open source che sviluppa modelli specializzati per ogni esigenza: dagli anime al fotorealismo, fino a stili artistici specifici.
Adobe Firefly incarna l’approccio di “IA responsabile”: è addestrato esclusivamente su immagini di Adobe Stock e contenuti di pubblico dominio, con licenze commerciali già incluse. È meno avanzato di Stable Diffusion, ma offre maggiori garanzie legali per l’uso commerciale.
Generazione video: la prossima frontiera
Il text-to-image è stato solo l’inizio. Nel 2024 l’IA ha fatto un salto di qualità nella generazione video:
Runway Gen 2 e Pika permettono di generare brevi clip video a partire da testo o immagini. La qualità è ancora disomogenea: gli oggetti a volte si deformano in modo innaturale e la fisica non è sempre convincente, ma i miglioramenti sono costanti, mese dopo mese.
Sora di OpenAI (annunciata a febbraio 2024, rilascio limitato) ha mostrato video fotorealistici e coerenti fino a un minuto di durata. I video demo hanno lasciato tutti a bocca aperta. Allo stesso tempo hanno spaventato molti, perché i deepfake erano già un problema ancora prima che l’IA fosse in grado di generare video credibili a partire dal testo.
3D e oltre
L’arte IA sta andando oltre le immagini bidimensionali:
Point E e Shap E (OpenAI) generano modelli 3D a partire da prompt testuali. La qualità è ancora limitata, ma la direzione è ormai evidente.
La tecnologia NeRF (Neural Radiance Fields) consente di generare scene 3D a partire da immagini 2D, aprendo nuove possibilità che spaziano dal cinema allo sviluppo di videogiochi, fino alla visualizzazione architettonica.
Musica, testo e multimodalità
La generazione musicale con l’IA (Suno, Udio) nel 2024 ha raggiunto un livello “più che buono”. L’IA non ha sostituito i musicisti, ma rende la produzione di musica funzionale e di sottofondo più semplice ed economica.
I modelli multimodali (GPT‑4 con capacità visive, Gemini) sono in grado di analizzare immagini, descriverle con il linguaggio e poi generare nuove immagini a partire da quel testo. Il confine tra IA testuale e IA visiva si sta facendo sempre più sottile.
Cosa ci aspetta: previsioni e possibilità
Breve termine (2025–2027)
Probabile:
- La generazione video raggiunge un livello di utilizzo mainstream
- La generazione di personaggi coerenti (la stessa persona in immagini diverse) diventa affidabile
- Maggiore chiarezza legale sul copyright, spinta dalle cause in corso
- Consolidamento del settore, con i player più piccoli acquisiti o costretti a chiudere
- La reazione contraria si intensifica, con alcune piattaforme e clienti che vietano l’arte generata dall’IA
Possibile:
- Generazione video in tempo reale durante videochiamate o live streaming
- L’arte generata dall’IA diventa uno strumento standard nei workflow creativi professionali
- Nascita dell’arte “certified human made” come categoria premium
- Grande mostra museale dedicata alla storia dell’arte IA (oltre le singole installazioni)
Medio termine (2027–2030)
Speculativo ma plausibile:
- Generazione di testo, immagini, video, 3D e audio unificata in modelli unici
- Modelli di IA personalizzati, addestrati su stili artistici individuali, diventano sempre più comuni
- L’integrazione AR/VR porta l’arte IA negli spazi fisici attraverso visori e headset
- I quadri normativi definiscono compromessi (probabilmente complessi) sull’uso dei dati di addestramento
- Nascono nuovi movimenti artistici nativi dell’IA, non semplici adattamenti di stili pre-IA
Nel lungo periodo: le grandi domande
L’IA supererà la creatività umana? È la domanda sbagliata: sono due cose diverse.
Gli artisti umani diventeranno obsoleti? Difficile. Anzi, con il mercato invaso da contenuti facili generati dall’IA, la domanda di opere “autenticamente umane” potrebbe persino aumentare.
Chi è il proprietario dell’arte generata dall’IA? È una questione ancora aperta nei tribunali. Oggi la legge sul copyright negli Stati Uniti afferma che non appartiene a nessuno (manca l’autorialità umana), ma è destinata a cambiare.
Come possiamo compensare gli artisti il cui lavoro viene usato per addestrare l’IA? È una domanda da miliardi di dollari, letteralmente. Le soluzioni possibili includono: licenze a pagamento, micropagamenti per utilizzo, sistemi di licenza obbligatoria sul modello dell’industria musicale. Ma al momento nessuna di queste è stata adottata su larga scala.
Dovrebbero esistere zone “AI-free”? Secondo alcuni, ambiti come i libri per bambini, i memoriali o le prove legali dovrebbero restare riservati ai creatori umani. Altri liquidano queste posizioni come luddismo. Il dibattito è ancora aperto.
Lezioni dalla storia
Ripercorrendo oltre 50 anni di storia dell’arte generata dall’IA, emergono alcuni schemi ricorrenti:
- Gli strumenti si democratizzano. AARON richiedeva competenze di programmazione. Le GAN richiedono conoscenze di machine learning. Gli strumenti moderni richiedono un account Discord. Ogni generazione è più accessibile della precedente.
- L’entusiasmo iniziale supera spesso la realtà. Ogni svolta tecnologica porta con sé proclami del tipo “l’arte è morta”. L’arte non muore. Si trasforma.
- I quadri legali ed etici restano indietro rispetto alla tecnologia. Stiamo ancora discutendo questioni di copyright legate a strumenti lanciati tre anni fa. Il diritto si muove lentamente; la tecnologia no.
- Le preoccupazioni sulla sostituzione dei lavori sono spesso fondate, ma incomplete. Sì, alcuni ruoli scompaiono. Ma ne nascono di nuovi. La fase di transizione è dolorosa, soprattutto per chi la vive in prima persona.
- L’arte sopravvive. La fotografia non ha ucciso la pittura. Gli strumenti digitali non hanno eliminato i media tradizionali. L’IA non ucciderà la creatività umana. Ma cambierà il modo in cui creiamo, perché creiamo e cosa creiamo.
Conclusione: il prossimo capitolo da scrivere
Dalla programmazione paziente di Harold Cohen nel 1973 ai milioni di persone che oggi generano immagini in pochi secondi, la storia dell’AI art è soprattutto il racconto di come è cambiato nel tempo il rapporto tra la creatività umana e le capacità computazionali.
Le domande che ci troviamo davanti oggi non sono più soprattutto tecniche: la tecnologia funziona e sta migliorando a grande velocità. Sono domande umane:
- Come possiamo fare in modo che l’IA amplifichi la creatività umana invece di sostituirla?
- Come garantire una remunerazione equa agli artisti il cui lavoro rende possibile l’IA?
- Chi può davvero partecipare a questo nuovo panorama creativo?
- Quali aspetti della creatività vogliamo mantenere esclusivamente umani?
- Come tutelare carriere e mezzi di sostentamento artistici durante la transizione tecnologica?
A queste domande non esistono risposte semplici. Servono confronto e negoziazione tra artisti, tecnologi, aziende, decisori politici e pubblico. La storia dell’arte IA non è affatto conclusa: stiamo vivendo proprio ora uno dei suoi capitoli più decisivi.
Una cosa è certa: ignorare l’IA non la farà scomparire, così come fingere che non ponga sfide reali. La strada da seguire richiede coinvolgimento: onesti sui problemi, aperti alle possibilità, determinati nel pretendere equità.
Chiedersi se l’IA possa davvero essere creativa forse significa porsi la domanda sbagliata. La creatività non è una qualità binaria, che o c’è o non c’è. Vive su uno spettro, nasce dalle collaborazioni, emerge da combinazioni inattese. Se i primi 50 anni dell’arte generata dall’IA ci hanno insegnato qualcosa, è che la creatività è più ampia — e più sorprendente — di quanto immaginassimo. E gli esseri umani, nel bene e nel male, sembrano decisi a condividerla.
Il prossimo capitolo si sta scrivendo ora. Contribuisci con consapevolezza.